
Die Zentralisierung Ihrer Daten ist, als würden Sie sich selbst in die Ecke stellen. Partitionieren Sie Daten nach Diensten, um diesen Fehler zu vermeiden. [...]

Microservice-Architekturen sind ein gängiges Modell für moderne Anwendungen und Systeme. Sie zeichnen sich dadurch aus, dass sie die geschäftliche Verantwortung einer großen Anwendung in verschiedene, separate Komponenten aufteilen, die unabhängig voneinander entwickelt, verwaltet, betrieben und skaliert werden können.
Microservice-Architekturen stellen ein effektives Modell für die Skalierung der Anwendung selbst dar und ermöglichen es größeren und unzusammenhängenden Entwicklungsteams, unabhängig an ihren Teilen zu arbeiten, während sie dennoch an der Erstellung einer großen Anwendung beteiligt sind.
In einer typischen Microservice-Architektur werden einzelne Dienste erstellt, die eine bestimmte Teilmenge der Geschäftslogik umfassen. Wenn sie miteinander verbunden werden, bildet der gesamte Satz von Microservices eine vollständige, groß angelegte Anwendung, die die komplette Geschäftslogik enthält.
Dieses Modell ist großartig für den Code, aber was ist mit den Daten? Oft haben Unternehmen, die einzelne Services für bestimmte Geschäftslogik erstellen, das Bedürfnis, alle Anwendungsdaten in einem einzigen, zentralisierten Datenspeicher abzulegen. Damit soll sichergestellt werden, dass alle Daten für jeden Dienst, der sie benötigt, verfügbar sind. Die Verwaltung eines einzigen Datenspeichers ist einfach und bequem, und die Datenmodellierung kann für die gesamte Anwendung konsistent sein, unabhängig davon, welcher Dienst sie verwendet.
Tun Sie das nicht. Hier sind drei Gründe, warum die Zentralisierung Ihrer Daten eine schlechte Idee ist.
Zentralisierte Daten sind schwer zu skalieren
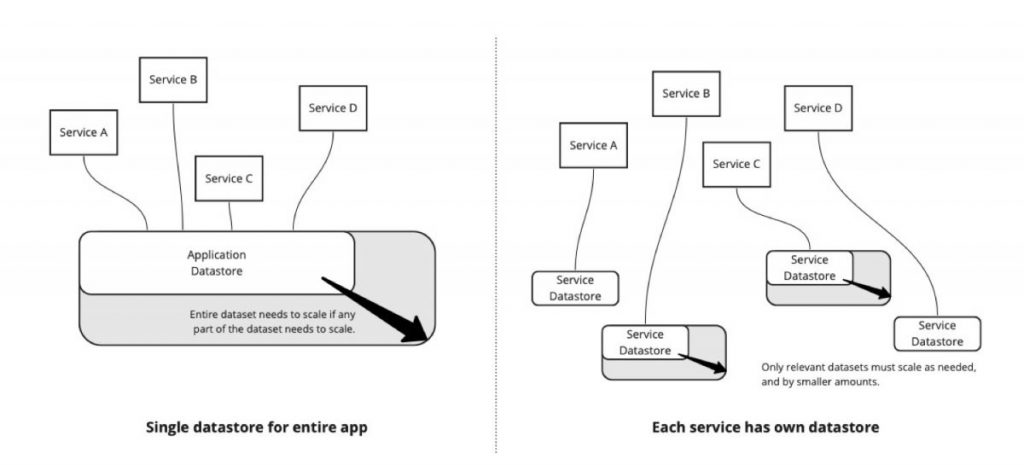
Wenn sich die Daten für Ihre gesamte Anwendung in einem einzigen zentralen Datenspeicher befinden, müssen Sie, wenn Ihre Anwendung wächst, den gesamten Datenspeicher skalieren, um die Anforderungen aller Dienste in Ihrer Anwendung zu erfüllen. Dies ist auf der linken Seite von Abbildung 1 dargestellt. Wenn Sie für jeden Dienst einen separaten Datenspeicher verwenden, müssen nur die Dienste skaliert werden, die einen erhöhten Bedarf haben, und die zu skalierende Datenbank ist eine kleinere Datenbank. Dies ist auf der rechten Seite von Abbildung 1 dargestellt.
Es ist viel einfacher, eine kleine Datenbank größer zu skalieren als eine große Datenbank noch größer zu skalieren.
Zentralisierte Daten sind später schwer zu partitionieren
Ein häufiger Gedankengang von Entwicklern einer neu erstellten App ist: „Ich muss mir jetzt keine Gedanken über die Skalierung machen; ich kann mir darüber Gedanken machen, wenn ich sie später brauche.“ Diese Sichtweise ist zwar weit verbreitet, aber sie ist ein Rezept für Skalierungsprobleme zum unpassendsten Zeitpunkt. Gerade wenn Ihre Anwendung populär wird, müssen Sie sich Gedanken darüber machen, ob Sie architektonische Entscheidungen überdenken müssen, nur um die wachsende Kundennachfrage zu erfüllen.
Eine häufige architektonische Änderung, die sich ergibt, ist die Notwendigkeit, Ihren Datenspeicher in kleinere Datenspeicher aufzuteilen. Das Problem ist, dass dies bei der erstmaligen Erstellung der Anwendung viel einfacher zu bewerkstelligen ist als später im Lebenszyklus der Anwendung. Wenn die Anwendung schon ein paar Jahre alt ist und alle Teile der Anwendung Zugriff auf alle Teile der Daten haben, wird es sehr schwierig zu bestimmen, welche Teile des Datensatzes in einen separaten Datenspeicher aufgeteilt werden können, ohne dass der Code, der die Daten verwendet, komplett neu geschrieben werden muss. Selbst einfache Fragen werden schwierig. Welche Dienste verwenden die Profiltabelle? Gibt es Dienste, die sowohl die Systems- als auch die Projects-Tabelle benötigen?
Und, noch schlimmer, gibt es einen Dienst, der eine Verknüpfung mit beiden Tabellen durchführt? Wofür wird er verwendet? Wo wird das im Code gemacht? Wie können wir diese Änderung refaktorisieren?
Je länger ein Datensatz in einem einzigen Datenspeicher bleibt, desto schwieriger ist es, diesen Datenspeicher später in kleinere Segmente zu trennen.
Indem Sie Daten nach Funktionalität in separate Datenspeicher aufteilen, vermeiden Sie Probleme, die mit der späteren Trennung von Daten aus verbundenen Tabellen zusammenhängen, und Sie reduzieren die Möglichkeit, dass unerwartete Korrelationen zwischen den Daten in Ihrem Code existieren.
Zentralisierte Daten machen Dateneigentum unmöglich
Einer der großen Vorteile der Aufteilung von Daten in mehrere Dienste ist die Möglichkeit, das Anwendungseigentum in verschiedene und trennbare Teile aufzuteilen. Das Eigentum an Anwendungen durch einzelne Entwicklungsteams ist ein zentraler Grundsatz der modernen Anwendungsentwicklung, der eine bessere organisatorische Skalierung und eine bessere Reaktionsfähigkeit auf auftretende Probleme fördert. Dieses Eigentumsmodell wird im STOSA-Entwicklungsmodell (Single Team Oriented Service Architecture) diskutiert.
Dieses Modell funktioniert hervorragend, wenn Sie eine große Anzahl von Entwicklungsteams haben, die alle zu einer großen Anwendung beitragen, aber auch kleinere Anwendungen mit kleineren Teams profitieren von diesem Modell.
Das Problem ist, dass ein Team, um Eigentümer eines Service zu sein, sowohl den Code als auch die Daten für den Service besitzen muss. Das bedeutet, dass ein Dienst (Dienst A) nicht direkt auf die Daten eines anderen Dienstes (Dienst B) zugreifen darf. Wenn Dienst A etwas benötigt, das in Dienst B gespeichert ist, muss er einen Diensteinstiegspunkt für Dienst B aufrufen, anstatt direkt auf die Daten zuzugreifen.
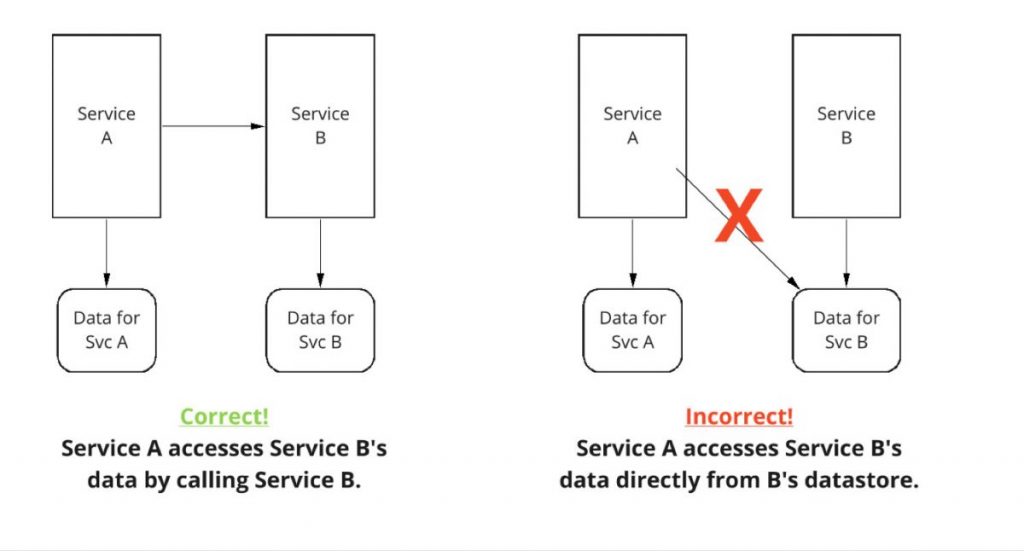
Dies ermöglicht Service B die vollständige Autonomie über seine Daten, deren Speicherung und Pflege.
Was ist also die Alternative? Wenn Sie Ihre serviceorientierte Architektur (SOA) aufbauen, sollte jeder Dienst seine eigenen Daten besitzen. Die Daten sind Teil des Dienstes und werden in den Dienst integriert.
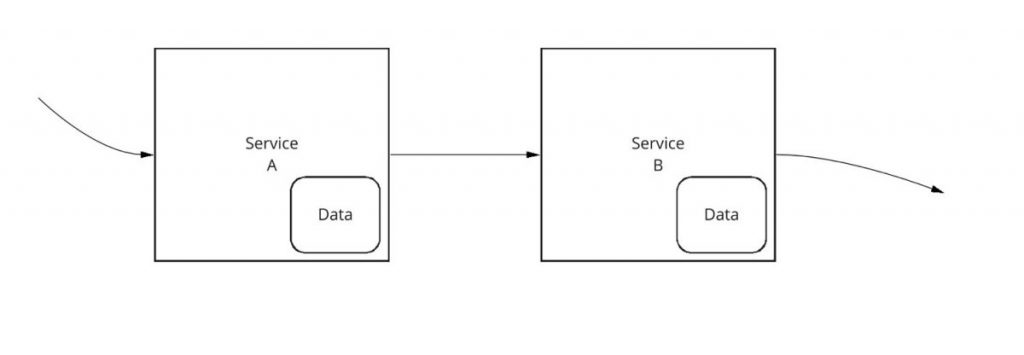
Auf diese Weise kann der Eigentümer des Dienstes die Daten für diesen Dienst verwalten. Wenn eine Schemaänderung oder eine andere strukturelle Änderung an den Daten erforderlich ist, kann der Eigentümer des Dienstes die Änderung implementieren, ohne dass ein anderer Eigentümer des Dienstes beteiligt ist. Wenn eine Anwendung (und ihre Dienste) wächst, kann der Service-Eigentümer Entscheidungen zur Skalierung und zum Refactoring der Daten treffen, um die erhöhte Last und die geänderten Anforderungen zu bewältigen, ohne dass andere Service-Eigentümer beteiligt sind.
Oft stellt sich die Frage: Was ist mit Daten, die wirklich zwischen Anwendungen ausgetauscht werden müssen? Dabei kann es sich um Daten wie Benutzerprofildaten oder andere Daten handeln, die in vielen Teilen einer Anwendung gemeinsam genutzt werden. Eine verlockende, schnelle Lösung könnte darin bestehen, nur die benötigten Daten über mehrere Dienste hinweg gemeinsam zu nutzen, wie in Abbildung 4 dargestellt. Jeder Dienst könnte über seine eigenen Daten verfügen und auch Zugriff auf die gemeinsam genutzten Daten haben.
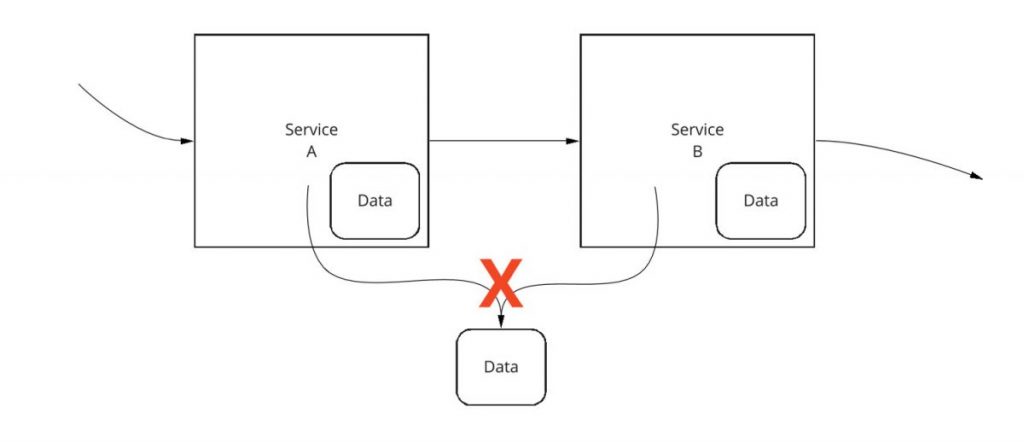
Ein besserer Ansatz ist, die gemeinsam genutzten Daten in einen neuen Dienst zu legen, der von allen anderen Diensten konsumiert wird, wie in Abbildung 5 gezeigt.
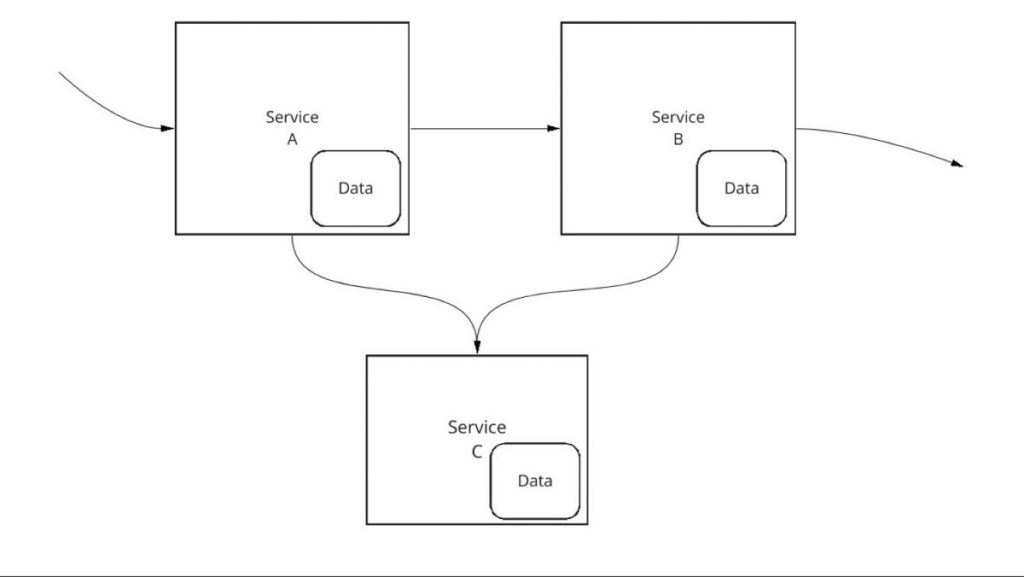
Der neue Dienst – Dienst C – sollte ebenfalls den STOSA-Anforderungen entsprechen. Insbesondere sollte es ein einziges, eindeutiges Team geben, das Eigentümer des Dienstes und damit auch der gemeinsam genutzten Daten ist. Wenn ein anderer Dienst, wie z. B. Dienst A oder Dienst B in diesem Diagramm, auf die gemeinsam genutzten Daten zugreifen muss, muss er dies über eine von Dienst C bereitgestellte API tun. Er kann entsprechende Entscheidungen über Skalierung, Refactoring und Aktualisierung treffen. Solange sie eine konsistente API für Service A und Service B bereitstellen, kann Service C alle Entscheidungen über die Aktualisierung der Daten treffen, die er benötigt.
Dies steht im Gegensatz zu Abbildung 4, in der sowohl Service A als auch Service B direkt auf die gemeinsamen Daten zugreifen. In diesem Modell kann kein einzelnes Team Entscheidungen über die Struktur, das Layout, die Skalierung oder die Modellierung der Daten treffen, ohne alle anderen Teams, die direkt auf die Daten zugreifen, mit einzubeziehen, wodurch die Skalierbarkeit des Anwendungsentwicklungsprozesses eingeschränkt wird.
Die Verwendung von Microservices oder einer anderen SOA ist eine großartige Möglichkeit, große Entwicklungsteams zu verwalten, die an großen Anwendungen arbeiten. Aber die Service-Architektur muss auch die Daten der Anwendung umfassen, sonst ist eine echte Service-Unabhängigkeit – und damit eine echte Skalierungsunabhängigkeit der Entwicklungsorganisation – nicht möglich.
*Lee Atchison ist ein anerkannter Vordenker im Bereich Cloud Computing und Anwendungsmodernisierung. Mit mehr als drei Jahrzehnten Erfahrung in den Bereichen Produktentwicklung, Architektur, Skalierung und Modernisierung hat Lee bei Amazon, Amazon Web Services (AWS), New Relic und anderen Unternehmen für moderne Anwendungen gearbeitet. Er wird in vielen Publikationen zitiert und war ein gefragter Redner auf der ganzen Welt. Lees neuestes Buch ist Architecting for Scale (O’Reilly Media). Sie können seine Bücher, Kurse, Artikel und Vorträge auf Twitter und LinkedIn nachlesen.









Be the first to comment