
Von einfachen Timern und Benchmarking-Modulen bis hin zu ausgefeilten, auf Statistiken basierenden Frameworks bieten diese Tools einen Einblick in die Leistung Ihres Python-Programms. [...]

Jede Programmiersprache hat zwei Arten von Geschwindigkeit: Entwicklungs- und Ausführungsgeschwindigkeit. In Python war es schon immer wichtiger, schnell zu schreiben als schnell auszuführen. Obwohl Python-Code fast immer schnell genug für die jeweilige Aufgabe ist, ist er manchmal doch nicht schnell genug. In diesen Fällen müssen Sie herausfinden, wo und warum er hinterherhinkt, und etwas dagegen tun.
Ein bekanntes Sprichwort der Softwareentwicklung und der Technik im Allgemeinen lautet: „Messen, nicht raten“. Bei Software ist es einfach zu vermuten, was falsch läuft, aber es ist nie eine gute Idee, dies zu tun. Statistiken über die tatsächliche Programmleistung sind immer das beste erste Werkzeug, um Anwendungen schneller zu machen.
Die gute Nachricht ist, dass Python eine ganze Reihe von Paketen bietet, mit denen Sie ein Profil Ihrer Anwendungen erstellen und herausfinden können, wo sie am langsamsten läuft. Diese Werkzeuge reichen von einfachen Einzeilern, die in der Standardbibliothek enthalten sind, bis hin zu ausgefeilten Frameworks zur Erfassung von Statistiken über laufende Anwendungen. Hier stelle ich neun der wichtigsten vor, von denen die meisten plattformübergreifend laufen und entweder in PyPI oder in der Standardbibliothek von Python verfügbar sind.
Time und Timeit
Manchmal braucht man nur eine Stoppuhr. Wenn Sie nur die Zeit zwischen zwei Codeschnipseln messen wollen, deren Ausführung Sekunden oder Minuten dauert, dann ist eine Stoppuhr mehr als ausreichend.
Die Python-Standardbibliothek verfügt über zwei Funktionen, die als Stoppuhren fungieren. Das Time-Modul hat die Funktion perf_counter, die den hochauflösenden Timer des Betriebssystems aufruft, um einen beliebigen Zeitstempel zu erhalten. Rufen Sie time.perf_counter einmal vor und einmal nach einer Aktion auf, und Sie erhalten die Differenz zwischen den beiden Werten. Auf diese Weise erhalten Sie einen unauffälligen, wenig aufwändigen – wenn auch nicht sehr anspruchsvollen – Weg zur Zeitmessung von Code.
Das Timeit-Modul versucht, so etwas wie ein echtes Benchmarking für Python-Code durchzuführen. Die Funktion timeit.timeit nimmt einen Codeschnipsel, führt ihn viele Male aus (die Vorgabe ist 1 Million Durchläufe) und ermittelt die dafür benötigte Gesamtzeit. Sie eignet sich am besten, um zu ermitteln, wie sich eine einzelne Operation oder ein Funktionsaufruf in einer engen Schleife verhält.
Der Nachteil von Time ist, dass es nichts weiter als eine Stoppuhr ist, und der Nachteil von Timeit ist, dass sein Hauptanwendungsfall Mikrobenchmarks für einzelne Zeilen oder Codeblöcke sind. Diese Module funktionieren nur, wenn Sie mit isoliertem Code arbeiten. Keines der beiden Module reicht für die Analyse des gesamten Programms aus – um herauszufinden, wo in den Tausenden von Codezeilen Ihr Programm die meiste Zeit verbringt.
cProfile
Die Python-Standardbibliothek enthält auch einen Profiler für die Analyse ganzer Programme, cProfile. Wenn cProfile ausgeführt wird, verfolgt es jeden Funktionsaufruf in Ihrem Programm und erstellt eine Liste, welche Funktionen am häufigsten aufgerufen wurden und wie lange die Aufrufe im Durchschnitt dauerten.
cProfile hat drei große Stärken. Erstens ist es in der Standardbibliothek enthalten, so dass es sogar in einer Standard-Python-Installation verfügbar ist. Zweitens erstellt es eine Reihe verschiedener Statistiken über das Aufrufverhalten – zum Beispiel trennt es die Zeit, die für die eigenen Anweisungen eines Funktionsaufrufs aufgewendet wird, von der Zeit, die für alle anderen von der Funktion aufgerufenen Calls benötigt wird. Auf diese Weise können Sie feststellen, ob eine Funktion selbst langsam ist oder ob sie andere Funktionen aufruft, die langsam sind.
Drittens, und vielleicht am besten von allen, können Sie cProfile beliebig einschränken. Sie können eine Stichprobe des gesamten Programmlaufs nehmen oder die Profilerstellung nur bei der Ausführung einer bestimmten Funktion einschalten, damit Sie sich besser darauf konzentrieren können, was diese Funktion tut und was sie aufruft. Dieser Ansatz funktioniert am besten, nachdem Sie die Dinge ein wenig eingegrenzt haben, aber er erspart Ihnen die Mühe, sich durch das Chaos einer vollständigen Profilaufzeichnung zu wühlen.
Das bringt uns zum ersten Nachteil von cProfile: Es generiert standardmäßig eine Menge Statistiken. Der Versuch, die richtige Nadel in all dem Heu zu finden, kann überwältigend sein. Der andere Nachteil ist das Ausführungsmodell von cProfile: Es fängt jeden einzelnen Funktionsaufruf ab, was einen erheblichen Mehraufwand verursacht. Das macht cProfile ungeeignet für das Profiling von Anwendungen in der Produktion mit Live-Daten, aber vollkommen in Ordnung, um sie während der Entwicklung zu profilieren.
FunctionTrace
FunctionTrace funktioniert in seinen Grundzügen wie cProfile: Sie geben den Namen des Skripts an, das Sie profilieren wollen, ohne dass Sie den Code instrumentalisieren müssen, und FunctionTrace erzeugt eine detaillierte Aufzeichnung der Funktionsaufrufe und der Speichernutzung im Laufe der Zeit. FunctionTrace verarbeitet auch Multithreading-/Multiprozess-Anwendungen, ohne dass Sie etwas Zusätzliches tun müssen.
Wie cProfile verwendet FunctionTrace keine Stichproben; jede Aktion wird aufgezeichnet. Die Profiling-Komponenten sind aus Geschwindigkeitsgründen in Rust geschrieben. Die Entwickler von FunctionTrace behaupten, dass der Mehraufwand für die Profilerstellung bei weniger als 10% liegt.
Die Trace-Daten werden im JSON-Format gespeichert, so dass Sie theoretisch jede Anwendung verwenden können, um sie zu parsen. Aber der große Vorteil von FunctionTrace ist, dass es den Firefox Profiler verwendet – der in jedem JavaScript-fähigen Browser läuft, nicht nur in Firefox – um die Ergebnisse in einem interaktiven Diagramm darzustellen.
Beachten Sie, dass die FunctionTrace-Profiling-Komponenten noch nicht unter Windows verfügbar sind; das Profiling kann nur auf Linux- oder Mac-Systemen durchgeführt werden.
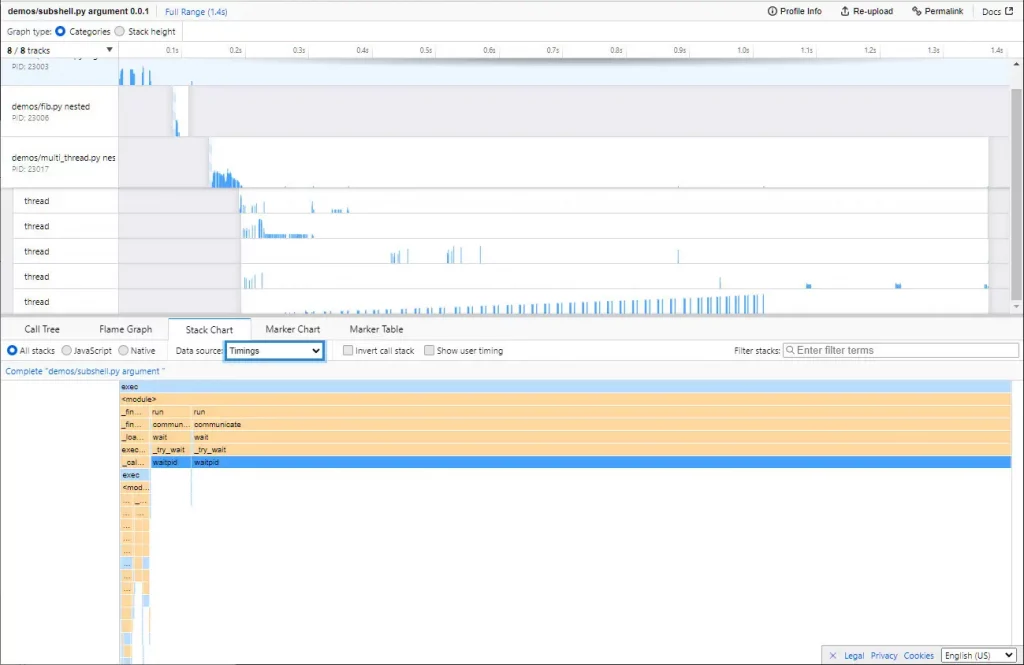
Palanteer
Palanteer ist eine relativ neue Ergänzung zum Python-Profiling-Arsenal und kann sowohl für Python- als auch für C++-Programme verwendet werden. Das macht es sehr nützlich, wenn Sie eine Python-Anwendung schreiben, die selbst erstellte C++-Bibliotheken einbindet, und Sie einen möglichst detaillierten Einblick in beide Komponenten Ihrer Anwendung haben möchten. Das Beste daran: Palanteer zeigt die Ergebnisse in einer GUI-Anwendung an, die auf dem Desktop läuft und live aktualisiert wird, während Ihr Programm läuft.
Die Instrumentierung von Python-Anwendungen ist so einfach, wie das Ausführen der Anwendung durch Palanteer, in der gleichen Weise, wie man cProfile verwendet. Funktionsaufrufe, Ausnahmen, Speicherbereinigung und Speicherzuweisungen auf OS-Ebene werden alle verfolgt. Die letzten beiden sind besonders nützlich, wenn sich herausstellt, dass die Leistungsprobleme Ihrer Anwendung mit der Speichernutzung oder den Objektzuweisungen zusammenhängen.
Ein großer Nachteil von Palanteer, zumindest im Moment, ist, dass Sie es komplett aus dem Quellcode erstellen müssen. Es sind noch keine vorkompilierten Binärdateien als installierbare Python Wheels verfügbar, also müssen Sie Ihren C++-Compiler auspacken und auch eine Kopie des CPython-Quellcodes zur Hand haben.
Pyinstrument
Pyinstrument funktioniert wie cProfile, indem es Ihr Programm verfolgt und Berichte über den Code erstellt, der die meiste Zeit in Anspruch nimmt. Aber Pyinstrument hat zwei große Vorteile gegenüber cProfile, die es lohnenswert machen, es auszuprobieren.
Erstens versucht Pyinstrument nicht, jede einzelne Instanz eines Funktionsaufrufs abzufangen. Es tastet den Aufrufstapel des Programms jede Millisekunde ab, so dass es weniger aufdringlich ist, aber immer noch empfindlich genug, um zu erkennen, was den größten Teil der Laufzeit Ihres Programms verschlingt.
Zweitens sind die Berichte von Pyinstrument viel übersichtlicher. Es zeigt Ihnen die wichtigsten Funktionen in Ihrem Programm, die die meiste Zeit in Anspruch nehmen, so dass Sie sich auf die Analyse der größten Übeltäter konzentrieren können. Außerdem können Sie diese Ergebnisse schnell und ohne großen Aufwand finden.
Pyinstrument hat auch viele der Annehmlichkeiten von cProfile. Sie können den Profiler als Objekt in Ihrer Anwendung verwenden und das Verhalten ausgewählter Funktionen anstelle der gesamten Anwendung aufzeichnen. Die Ausgabe kann auf beliebige Art und Weise gerendert werden, auch als HTML. Wenn Sie die gesamte Zeitachse der Aufrufe sehen möchten, können Sie auch das einrichten.
Zwei Vorbehalte sind ebenfalls zu beachten. Erstens funktionieren einige Programme, die C-kompilierte Erweiterungen verwenden, wie z. B. die mit Cython erstellten, möglicherweise nicht richtig, wenn sie mit Pyinstrument über die Befehlszeile aufgerufen werden. Sie funktionieren aber, wenn Pyinstrument im Programm selbst verwendet wird – z.B. indem man eine main()-Funktion mit einem Pyinstrument-Profiler-Aufruf umhüllt.
Die zweite Einschränkung: Pyinstrument kann nicht gut mit Code umgehen, der in mehreren Threads läuft. Py-spy, weiter unten beschrieben, könnte hier die bessere Wahl sein.
Py-spy
Py-spy funktioniert wie Pyinstrument, indem es den Zustand des Aufrufstapels eines Programms in regelmäßigen Abständen abtastet, anstatt zu versuchen, jeden einzelnen Aufruf aufzuzeichnen. Anders als PyInstrument hat Py-spy Kernkomponenten, die in Rust geschrieben sind (Pyinstrument verwendet eine C-Erweiterung) und läuft außerhalb des Prozesses mit dem profilierten Programm, so dass es sicher mit Code verwendet werden kann, der in der Produktion läuft.
Diese Architektur erlaubt es Py-spy, etwas zu tun, was viele andere Profiler nicht können: Multithreading oder Subprocessing von Python-Anwendungen. Py-spy kann auch C-Erweiterungen profilieren, aber diese müssen mit den Symbolen kompiliert werden, um nützlich zu sein. Und im Falle von Erweiterungen, die mit Cython kompiliert wurden, muss die generierte C-Datei vorhanden sein, um die richtigen Trace-Informationen zu sammeln.
Es gibt zwei grundlegende Wege, eine Anwendung mit Py-spy zu untersuchen. Sie können die Anwendung mit dem Aufzeichnungsbefehl von Py-spy ausführen, der nach Abschluss des Laufs ein Flammendiagramm erzeugt. Oder Sie können die Anwendung mit dem top-Befehl von Py-spy ausführen, der eine live-aktualisierte, interaktive Anzeige des Innenlebens Ihrer Python-Anwendung erzeugt, die auf die gleiche Weise wie das Unix-Dienstprogramm top angezeigt wird. Einzelne Thread-Stacks können auch von der Kommandozeile aus ausgegeben werden.
Py-spy hat einen großen Nachteil: Es ist hauptsächlich dazu gedacht, ein ganzes Programm oder einige Komponenten davon von außen zu profilieren. Es erlaubt Ihnen nicht, nur eine bestimmte Funktion auszuschmücken und zu testen.
Snakeviz
Die gebräuchlichste Methode zur Visualisierung von Daten aus einer cProfile-Ablaufverfolgung ist ein anderes Modul der Standardbibliothek, pstats. Das Problem ist, dass pstats reine Textberichte erzeugt, die nicht immer die Art von Visualisierung bieten, die Sie für Profilstatistiken benötigen.
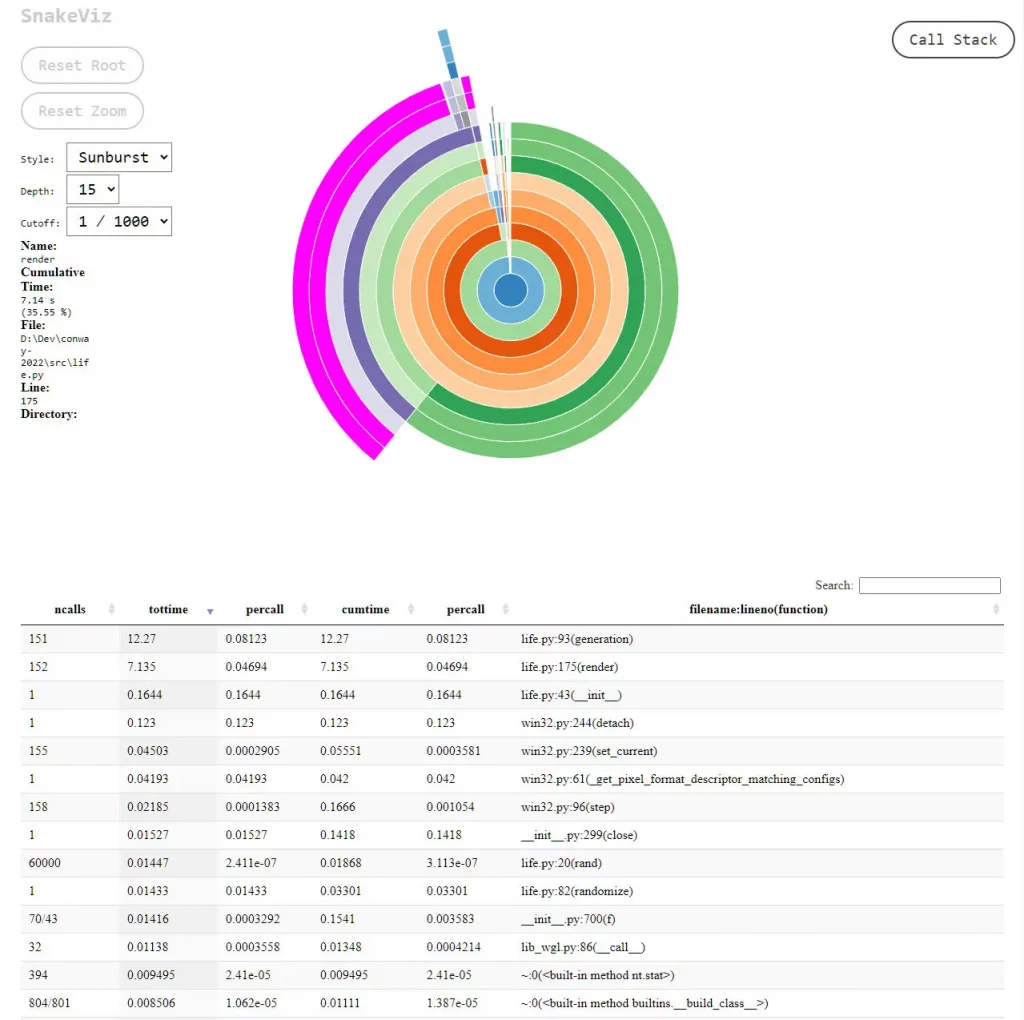
Snakeviz nimmt die von cProfile generierten Daten und erzeugt leicht lesbare, interaktive Grafiken, die mit HTML gerendert werden. Es stehen zwei Arten von Diagrammen zur Verfügung: der „Eiszapfen“ und der „Sonnenstrahl“, die jeweils auf einen Blick zeigen, wo Ihr Programm die meiste Zeit verbraucht. Jedes Segment des Diagramms stellt die Aufrufzeit für eine Funktion dar. Klicken Sie einfach auf ein Segment, um eine Funktion zu vergrößern, und Sie können die Zeit, die alles im Stapel darunter verbraucht, ebenfalls überprüfen.
Snakeviz generiert auch eine durchsuchbare und sortierbare HTML-Tabellenansicht der Trace-Daten; sie ist wie eine interaktivere Version der von pstats erstellten Traces. Selbst wenn Sie sich nicht mit den Diagrammen befassen, ist die tabellarische Ansicht der Trace-Daten an sich schon eine sehr leistungsfähige Methode, um die cProfile-Daten sinnvoll zu nutzen.
Yappi
Yappi („Yet Another Python Profiler“) hat viele der besten Eigenschaften der anderen hier besprochenen Profiler und einige, die von keinem von ihnen angeboten werden. PyCharm installiert Yappi standardmäßig als Profiler der Wahl, so dass Benutzer dieser IDE bereits eingebauten Zugriff auf Yappi haben.
Um Yappi zu verwenden, schmücken Sie Ihren Code mit Anweisungen zum Aufrufen, Starten, Stoppen und Erstellen von Berichten für die Profiling-Mechanismen. Yappi lässt Sie zwischen „Wall Time“ und „CPU Time“ wählen, um die benötigte Zeit zu messen. Erstere ist nur eine Stoppuhr; letztere misst über systemeigene APIs, wie lange die CPU tatsächlich mit der Ausführung von Code beschäftigt war, wobei Pausen für E/A oder schlafende Threads ausgelassen werden. Die CPU-Zeit gibt Ihnen das genaueste Gefühl dafür, wie lange bestimmte Operationen, wie z. B. die Ausführung von numerischem Code, tatsächlich dauern.
Ein sehr schöner Vorteil der Art und Weise, wie Yappi die Statistiken von Threads abruft, ist, dass man den Thread-Code nicht ausschmücken muss. Yappi stellt eine Funktion, yappi.get_thread_stats(), zur Verfügung, die Statistiken von jeder aufgezeichneten Thread-Aktivität abruft, die Sie dann separat auswerten können. Die Statistiken können mit hoher Granularität gefiltert und sortiert werden, ähnlich wie mit cProfile.
Schließlich kann Yappi auch Greenlets und Coroutines profilieren, was viele andere Profiler nicht oder nur schwer können. Angesichts der zunehmenden Verwendung von asynchronen Metaphern in Python ist die Fähigkeit, Profile für nebenläufigen Code zu erstellen, ein mächtiges Werkzeug.
*Serdar Yegulalp ist Senior-Autor bei InfoWorld und konzentriert sich auf maschinelles Lernen, Containerisierung, Devops, das Python-Ökosystem und regelmäßige Reviews.









Be the first to comment