
Viele datengesteuerte Unternehmen suchen heute nach einer einheitlichen Ansicht all ihrer Kundendaten. MongoDB hat zu diesem Zweck eine 10-stufige Methode entwickelt, mit sich übermäßig kompliziertes Datenmanagement auf lange Sicht effektiv vereinfachen lässt. [...]

Das moderne Unternehmen agiert datenfokussiert. Die Fähigkeit, schnell auf Informationen zugreifen und reagieren zu können, ist zu einem entscheidenden Wettbewerbsvorteil geworden. Geschäftsdaten sind jedoch oft isoliert und umständlich fragmentiert, was den Zugriff erschwert. Um einen größeren Wettbewerbsvorteil aus Ihren Informationen gewinnen zu können, benötigen Sie eine übersichtliche Einzelansicht (Single-View) all Ihrer Daten.
Für viele Unternehmen ist die Verwaltung von Daten ein ermüdender, komplizierter Prozess, der in der Regel mehrere Datenquellen mit variabler Struktur, Ingestion und Transformation, das Laden der Daten in eine Betriebsdatenbank und die Unterstützung durch Geschäftsanwendungen umfasst, die eben diese Daten benötigen. Analytics, Business Intelligence (BI) und Reporting-Tools erfordern Zugriffe auf die Daten, die wiederum häufig in ein separates Data Warehouse oder einen Data Lake eingespeist sind. Unterschiedliche Schichten des Datamanagements müssen natürlich außerdem allen Sicherheitsprotokollen, Information Governance Standards und anderen betrieblichen Anforderungen entsprechen.
Zu oft führt diese Komplexität dazu, dass Informationen in Silos verloren gehen. Bestimmte Systeme sind eher darauf ausgelegt, die momentanen Anforderungen direkt zu erfüllen, statt sich sorgfältig an den vorhandenen Anwendungszustand anzupassen – oder ein Dienst benötigt zusätzliche, bislang ungenutzte Attribute, um neue Funktionen unterstützen zu können. Neue Datenquellen häufen sich aufgrund von Unternehmenszusammenschlüssen oder -übernahmen. Informationen über eine einzelne Geschäftseinheit – wie beispielsweise einen Kunden – gehen in einem Dutzend verschiedener, voneinander getrennter Stellen leicht unter.
„Wir wissen, dass Daten überall um uns herum existieren“, so Mat Keep, Direktor für Produkt- und Marktanalyse bei MongoDB, dem Unternehmen hinter der gleichnamigen, Open-Source- und dokumentenorientierten NoSQL-Datenbank. „Und die Masse an verfügbaren Daten wächst jedes Jahr um 40 bis 50 Prozent. Mobil, Web, Sensordaten, soziale Netzwerke. All diese Daten in einer einzigen Ansicht zu vereinen wird zunehmend zur Priorität. Die Daten sind sehr komplex, oft in Silos, selten konsistent und nur schwer umsetzbar. Viele Unternehmen versuchen daher schon lange, eine einheitliche Ansicht zu schaffen. “
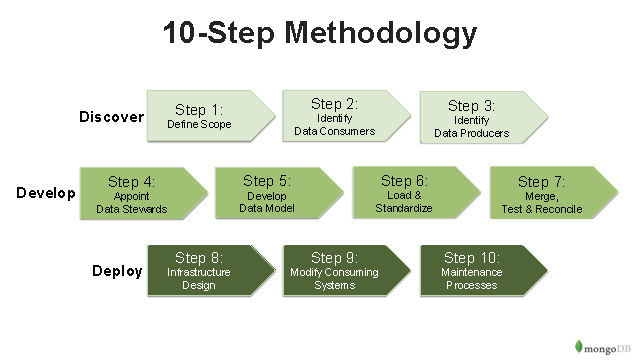
Um Organisationen dabei zu helfen, hat MongoDB eine 10-stufige Methode entwickelt, die dabei helfen soll, eine einheitliche Sicht auf alle Daten zu erhalten – basierend auf ihrer mühsam erlangten Erfahrung aus jeweiligen Kundenprojekten.
Schritt 1: Definieren Sie den Projektumfang und das Sponsoring
Kunden wagen sich oft mit sehr ehrgeizigen Plänen an Single-View-Projekte, meint Keep. Es ist gut, ein Ziel vor Augen zu haben, aber gleich alle Kundendaten aus jedem möglichen System in die Single-View-Ansicht übertragen zu wollen, ist ein Fehler, der häufig vorkommt.
„Nach eigener Erfahrung kommt es dem Versuch gleich, das Meer zum Kochen bringen zu wollen. Wenn man versucht, alle verfügbaren Daten gleich in die erste Phase des Projekts zu übertragen, ist das vielleicht etwas zu viel des Guten.“, meint er. „Was sich für uns bewährt hat, ist, sich auf ein einzelnes Geschäftsproblem zu konzentrieren.“
Vielleicht möchten Sie ja die Mean Time to Resolve (MTTR) in Ihrem Call Center reduzieren? Wenn Sie den Umfang Ihres Projekts auf dieses spezifische Ziel beschränken, wird es viel einfacher, die Daten zu identifizieren, die für den Erfolg am wichtigsten sind.
„Man sollte wirklich erst laufen, bevor man rennt“, so Keep. „Beginnen Sie mit einem bestimmten Geschäftsproblem, das aus einer definierten Menge an Daten besteht, aus der Sie auswählen können – und mit einer genau definierten Menge an Zielen, an denen Sie Ihren Erfolg messen können.“
Dies wird Ihnen auch dabei helfen, die wichtigsten Interessengruppen zu ermitteln, die von Ihrem Vorhaben profitieren können. Zwar werden sie das Projekt nicht jeden Tag leiten, doch sie können dabei helfen, die notwendigen Ressourcen zu erhalten, um sicherzustellen, dass das Projekt auch erfolgreich verläuft.
Schritt 2: Ermitteln Sie die Datennutzer
Sobald Sie das Problem benannt haben, das Sie lösen möchten, besteht der nächste Schritt darin, ein Verständnis für die jeweiligen Nutzer der Datenansicht aufzubauen, die Sie aufstellen wollen. Um alles Notwendige in die Wege leiten zu können, müssen Sie verstehen, wer die Datennutzer sind, wie sie arbeiten und wie Sie letztlich ihre Arbeit vereinfachen können.
„Nehmen Sie sich eine Auszeit dafür“, rät Keep. „Beobachten Sie sie. Wie fragen sie die Daten ab? Per Textsuche? Eine Suche nach Kundennummer? Sie können dem Ganzen nicht genug Aufmerksamkeit schenken und Sie können auch nicht genug Daten bekommen.“
So hat MongoDB beispielsweise der Versicherungsgesellschaft MetLife geholfen, eine Single-View-Ansicht über all ihre Call-Center-Mitarbeiter zu erhalten, so Keep. Die jeweilige Beobachtung ergab, dass die Call-Center-Mitarbeiter des Unternehmens über 15 verschiedene Bildschirme nutzen mussten, um allgemeine Kundenfragen zu beantworten. Indem sie genau verfolgten, was sie tagtäglich taten – sowie die Fragen, die sie für die Kunden beantworten mussten, oder was sie brauchten, um diese Antworten zu erhalten –, waren MetLife und MongoDB in der Lage, ein wesentlich einfacheres System zu erschaffen.
Schritt 3: Ermitteln Sie die Datenproduzenten
Der dritte Schritt geht oft mit dem zweiten Schritt einher und besteht darin, die Datenquellen der Daten zu ausfindig zu machen, die Sie für Ihr Projekt benötigen.
„Das kann bedeuten, dass Sie diese neuen Datenquellen erst noch erschaffen müssen, doch in der Regel existieren die notwendigen Daten bereits“, sagt Keep. „Man muss nur wissen, wo sie sind und wie man an sie herankommt. Manchmal reicht es, eine bestehende Anwendung zu ändern, um ein neues Attribut zu erfassen, oder etwas zu digitalisieren, das zuvor manuell war.“
Wie Schritt 2 hilft Ihnen dieser Schritt dabei, die korrekten Bedingungen für Ihr Vorhaben zu ermitteln.
Schritt 4: Ernennen Sie Datenverwalter
Alle vorherigen Schritte dieser Methodik gehören in die Entdeckungsphase Ihres Single-View-Projekts. Dabei geht es vor allem darum, den Anforderungsrahmen zu ermitteln. Mit Schritt 4 treten Sie nun in die Entwicklungsphase ein, indem Sie Datenverantwortliche für die Daten in den jeweiligen Quellsystemen ernennen. Ihre Datenverwalter spielen sowohl bei der Erstellung Ihres Single-View-Projekts als auch bei der laufenden Wartung eine wichtige Rolle.
„Oft gehören ihnen die in Schritt 2 oder 3 entdeckten Datenquellen“, erklärt Keep. „Sie wissen, in welchen Tabellen die Daten gespeichert sind, wie sie formatiert sind und wie sie extrahiert werden. Sie wissen, ob es eine saubere Möglichkeit gibt, an die Daten zu kommen, ohne die Kerndatensysteme zu unterbrechen.“
Schritt 5: Entwickeln Sie das Single-View-Modell
Dieser kritische Schritt wird alles Folgende beeinflussen, aber es wird Ihnen weniger beängstigend vorkommen, wenn Sie Ihre erste Upfront Discovery erfolgreich gemeistert haben, meint Keep. Finden Sie heraus, um welche Art der Daten es sich handelt, wo sie sich befinden und wie Sie sie am besten abfragen müssen.
“ [Bei diesem Schritt] können wir uns genau ansehen, welche Daten obligatorisch und welche optional sind“, sagt Keep. „Für Ihre Bewerbung sind möglicherweise die E-Mail-Adresse, das Geburtsdatum und die Kreditkartennummer obligatorisch. Das Social-Media-Konto ist dagegen vermutlich optional. Dann ermitteln Sie, welche Daten jeweils indiziert werden müssen. Dadurch werden die Anfragen an die jeweiligen Anwendungen beschleunigt.“ Hier könnte eine Datenbank mit flexiblem Datenmodell wirklich helfen. Dann brauchen wir nicht alle optionalen Felder zu kennen, sondern können sie dann hinzufügen, wenn wir sie brauchen. Wir brauchen in diesem Fall nur die obligatorischen Daten.“
Schritt 6: Daten laden und standardisieren
Sobald Sie Ihr Single-View-Datenmodell erstellt haben, müssen Sie noch definieren, wie die Daten in der Einzelansicht dargestellt werden sollen. Sie sollten allgemeine Feldnamen für die zu erfassenden Attribute erstellen. Ihre unterschiedlichen Datenquellen könnten „Geburtstag“, „Geburtsdatum“ und „GB“ erfassen – diese Feldnamen sollten Sie natürlich standardisieren.
„Auf der sechsten Stufe stellen wir sicher, dass wir alle Daten aus unseren Quellsystemen so konvertieren, dass sie mit dieser Standardisierung übereinstimmen“, erklärt Keep. „Dann beginnen wir mit der Erst-Beladung der Datenbank.“
„Bei der erstmaligen Verwendung haben Sie noch eine leere Single-View-Datenbank, in die Sie alle Daten aus Ihren möglichen Quellsystemen hineinziehen, damit sie an die von Ihnen definierten Anforderungen angepasst werden“, fügt er hinzu. „Dann werden Sie Updates für die Einzelansicht ansetzen müssen. Sie können dies schubweise tun; was wir in letzter Zeit jedoch häufiger sehen, ist, dass viele eine weitaus aktuellere Ansicht wünschen. Zu diesem Zweck ist [Apache] Kafka in letzter Zeit sehr beliebt. Es bietet beinahe eine Echtzeit-Version der Daten. Diese nennen wir ‚Delta Load‘.“
Schritt 7: Übereinstimmen, zusammenführen und abstimmen
Obwohl Sie Ihre Daten im vorherigen Schritt bereits standardisiert haben, müssen Sie jetzt noch Algorithmen verwenden, die ermitteln sollen, wo sich noch Datensätze befinden, die noch nicht ordentlich aufeinander abgestimmt wurden. Beispielsweise kann ein Geschäftsreiseantrag Unterlagen enthalten, die sich auf ‚Mat Keep‘, ‚Mr. Keep‘ und ‚Matthew Keep‘ beziehen. Ihre Single-View-Anwendung muss diese Datensätze abgleichen, zusammenführen und miteinander abstimmen.
„Das ist wirklich eine der schwierigsten Phasen“, so Keep. „Hier kommt Matching und Merging ins Spiel. Sie könnten beispielsweise eindeutige Identifikatoren wie Kreditkartennummern verwenden: Suchen Sie nach diesen Feldern, um festzustellen, ob es sich um dieselbe Person handelt. Haben Sie diese kanonischen Daten nicht oder kommt es zu einem Tippfehler, müssen Sie die Dateiattribute abfragen. Auf diese Weise können Sie Datensätze mit ähnlichen Attributen zusammenfassen und dann entscheiden, ob es sich um die gleiche Person handelt oder nicht. Sie können natürlich auch entsprechende Tools verwenden, um diesen Vorgang zu automatisieren.“
Maschinelles Lernen könnte hier eine wesentliche Rolle spielen.
Schritt 8: Architekturdesign
Der Architekturentwurf markiert den Beginn der Bereitstellungsphase Ihres Single-View-Projekts.
„Hier kommen wir physisch ins Spiel“, sagt Keep. „Es geht darum sicherzustellen, dass die zugrunde liegenden Systeme die Leistungsziele sowie die Verfügbarkeits- und Sicherheitsziele des Systems erfüllen.“
Bei diesem Schritt implementieren Sie einen angemessenen Sicherheitsschutz für persönlich identifizierbare Informationen (PII) und stellen sicher, dass das System gegen Störungen und Ausfälle resistent ist.
Schritt 9: Ändern Sie die Verbrauchersysteme
Bei diesem Schritt betrachten Sie alle Systeme, die die Daten verwenden, genauer und stellen sicher, dass die Anwendungen auf die Einzelansicht verweisen. In den meisten Fällen bedeutet dies, RESTful-APIs zu erstellen, von denen aus die Anwendungen ihre Daten abrufen können.
Schritt 10: Implementieren Sie Wartungsprozesse
Kein Business-System ist statisch. Sie ändern sich ständig, wenn neue Prozesse hinzugefügt oder Fehler behoben werden. Sie können das perfekte Datenmodell erstellen, und es bleibt genau so für fünf Tage, bis sich eines der Quellsysteme ändert oder ausfällt. Aus diesem Grund ist ein flexibles Datenmodell der Schlüssel, um Ihr Single-View-Projekt richtig zu erhalten. Das Datenmodell muss schließlich mit sich schnell ändernden Quellsystemen Schritt halten können.
„Schritt 10 ist ein Meta-Schritt“, erklärt Keep. „Um die Einzelansicht beibehalten zu können, müssen Sie die vorherigen neun Schritte zurückgehen und das Datenmodell kontinuierlich aktualisieren. Schritt 10 ist eine Schleife um die vorherigen Prozesse herum. Sie müssen die Verwaltungsprozesse stetig ändern, damit die Single-View-Ansicht aktuell bleibt. Der Datenverwalter ist in Wirklichkeit der Hüter des Quellsystems: Wenn neue Anwendungsfunktionen eingeführt werden, müssen [die Datenverwalter] mit dem Single-View-Team zusammenarbeiten, um sie über Änderungen zu informieren. Sie müssen auf Abruf bereit sein; das Single-View-Team muss in der Lage sein, die Änderungen sofort anzupassen, und die Datenverwalter sollten eng mit dem Entwicklungsteam zusammenarbeiten. “
Das Single-View-Maturity-Modell
Sobald Sie mehrere Single-View-Projekte auf dem Buckel haben und sich mit der Methodik soweit wohlfühlen, können Sie mit Ihrer Vision ehrgeiziger werden.
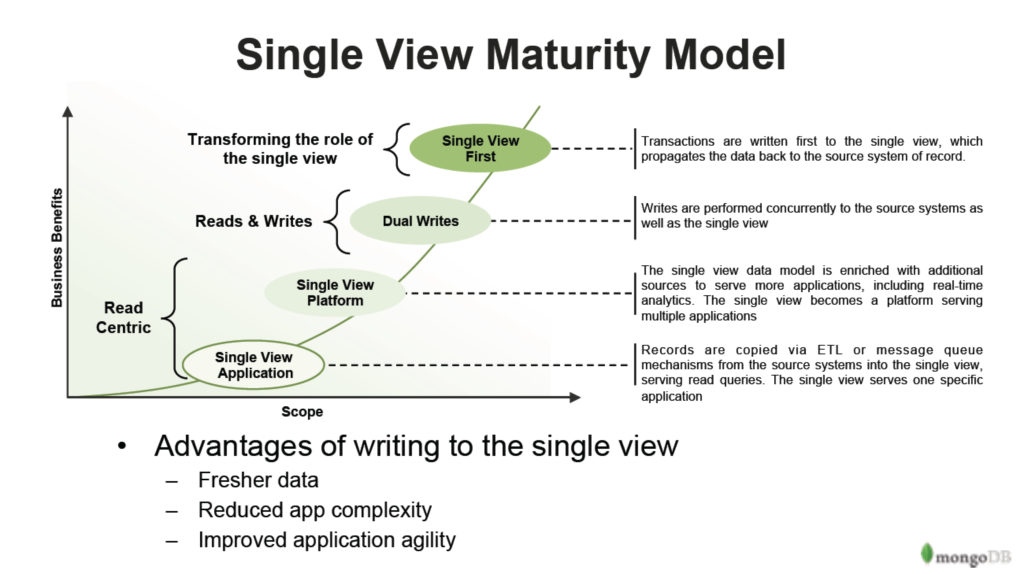
„Der Versuch, den Ozean zum Kochen zu bringen, mag verlockend sein, aber es ist effektiver, sich an ein definiertes Problem zu halten.“, so Keep.
„Wenn sich die Einzelansicht einmal bewährt hat, wissen Sie auch, dass sie funktioniert, und die Kunden werden im Umgang mit ihr immer abenteuerlicher“, fügt er hinzu. „Sie fangen an, in die Einzelansicht hineinzuschreiben, um eben noch aktuellere Daten zu erhalten. Wir haben einige Kunden wie die International Banking Group, die einen Single-View-Ansatz verfolgen. Wenn sie neue Funktionen brauchen, implementieren sie sie zuerst in der Einzelansicht. Haben sie alle Änderungen am Backend-Quellsystem vorgenommen, kehren sie zu den anderen Quellsystemen zurück. “
*Thor Olavsrud ist Senior Writer bei CIO.com









Be the first to comment