
Die Grenzen zwischen Korrelation und Kausalität sind fließend. Gerade deshalb sollten sie sorgsam gezogen und strikt beachtet werden. Auch im Business kann ihre Verwechslung zu fatalen Fehlschlüssen führen. [...]

Die Grenzen zwischen Korrelation und Kausalität sind fließend. Gerade deshalb sollten sie sorgsam gezogen und strikt beachtet werden. Auch im Business kann ihre Verwechslung zu fatalen Fehlschlüssen führen.
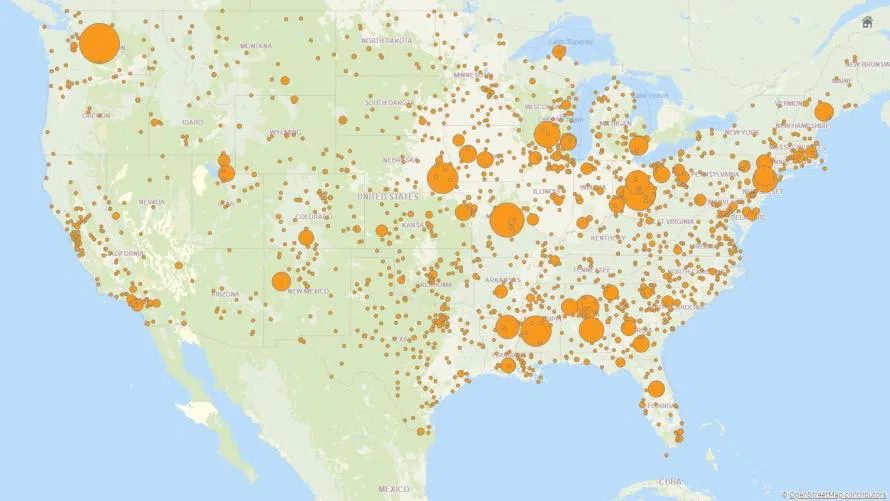
Aktuell grassieren in Corona-Foren zwei Karten der USA, die beide auffällige statistische Ähnlichkeiten aufweisen. Die erste zeigt die Zahl der registrierten Corona-Fälle im Jahr 2020 (orange):
Die zweite zeigt die Zahl der installierten 5G-Masten (blau):
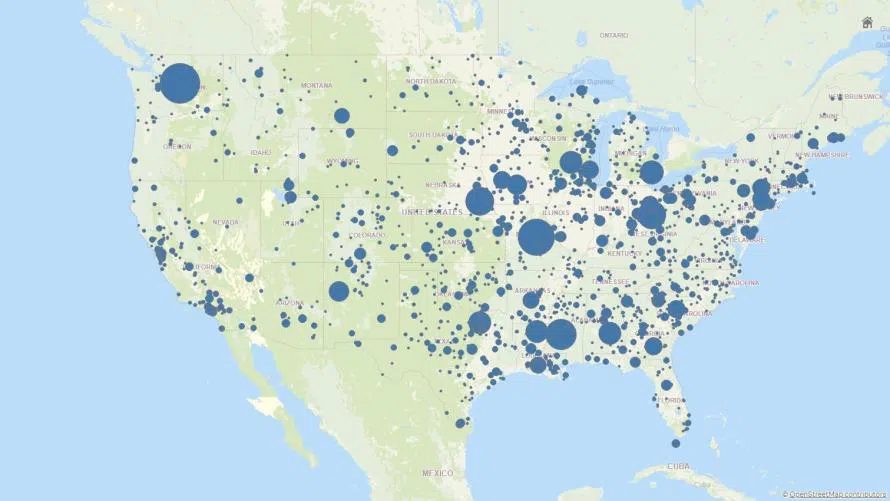
Die Korrelation ist offensichtlich. Daraus jedoch die Kausalität ableiten zu wollen, dass 5G-Masten Corona-Ausbrüche fördern, wäre ein logischer Kurzschluss. Denn der Grund für die Ähnlichkeit ist die schlichte Tatsache, dass an solchen Stellen in den USA mit der größten Bevölkerungsdichte nicht nur die Corona-Häufigkeit am größten ist, sondern eben auch die Anzahl der Handy-Nutzer. Sie sähe ähnlich aus, wenn man statt der 5G-Karte eine Übersicht der Verkehrsunfallzahlen oder der Kriminalitätshäufigkeit in den USA nähme. Auch daraus könnte man nicht auf eine direkte kausale Beziehung zwischen Verkehrsdichte, respektive Verbrechensrate, und der Häufigkeit von Corona-Fällen schließen.
Das schwierige Verhältnis von Korrelation und Kausalität
Für Unternehmen ist es wichtig, solche Verwechslungen zwischen Korrelation und Kausalität zu vermeiden. Nur so können sie beide für sich nutzbar machen. Eine Korrelation ist zuerst einmal eine auffällige Übereinstimmung statistischer Größen. Kausalität dagegen liegt erst dann vor, wenn eine Beziehung von Ursache und Wirkung (wenn – dann) besteht.
Um die Differenzierung zwischen beiden so schwierig wie möglich zu machen, sind jedoch viele Abstufungen möglich. So wird beispielsweise mehr Speiseeis verkauft, wenn viele Menschen einen Sonnenbrand haben. Auf den ersten Blick besteht zwischen beiden Phänomenen kein kausaler Zusammenhang. Sonnenbrand erhöht den Appetit auf Speiseeis keineswegs signifikant.
Sieht man jedoch genauer hin, dann erkennt man eine kausale Beziehung, die beiden Verteilungen zugrunde liegt: das heiße Wetter. Je besser das Wetter ist, desto mehr Menschen haben einen Sonnenbrand. Und bei Sonnenschein haben auch mehr Menschen Lust auf ein Eis. Hier existiert also genau wie bei Corona und 5G sowohl ein korrelativer als auch ein indirekter kausaler Zusammenhang. Wie stark solche Zusammenhänge sind, hängt immer vom Anwendungsfall ab.
Korrelation und Kausalität im Business
Bei der Nutzbarmachung von Korrelationen und Kausalitäten für Unternehmen gilt es daher im Kontext von Analytics und Data Science festzulegen: Wollen wir bestimmte Zusammenhänge in Daten verstehen oder wollen wir sie nur zu einem konkreten Zweck nutzen? Denn klar ist: Möchte man den Speiseeisverbrauch vorhersagen und sollten Wetterdaten aus welchen Gründen auch immer dafür nicht verfügbar sein, so wäre die Anzahl registrierter Sonnenbrände nach wie vor eine hilfreiche, erklärungsstarke und handlungsweisende Variable, unabhängig davon wie direkt der kausale Zusammenhang ist.
Viele Fragen im Unternehmenskontext können durch Data Science und Machine Learning beantwortet werden, ohne dass dabei explizit kausale Zusammenhänge identifiziert werden. Möchte etwa der Einkauf vorhersagen, wie lange der Lieferant wirklich braucht, bis er die Ware liefert, oder möchte der Produktionsleiter im Vorfeld wissen, wie lange die Endmontage dauert, so ist oft nicht ausschlaggebend, woran das im Detail liegt, also welche Kausalketten dafür existieren. Für die Beantwortung dieser Fragen sind präzise Zahlen, ein niedrigerer Lagerbestand und höhere Termintreue meist viel wichtiger.
Für korrelative Analysen nutzen Data Scientist in der Regel Frameworks, die auch für Machine Learning genutzt werden. Einige der bekanntesten sind beispielsweise scikit-learn für die Programmiersprache Python und mlr und caret für R. Die daraus gewonnen Korrelationen sind wertvoll bei der Identifikation von Einflussgrößen, der Erhöhung der Differenzierungsstärke oder für präzisen Vorhersagen. Der Maschinenbau liefert mit analytischen Anwendungen wie Predictive Maintenance und Predictive Quality (Ausschluss-Analyse) plakative Beispiele dafür.
Das Ziel bestimmt den Weg
Für andere Anwendungsszenarien dagegen ist die Identifizierung von kausalen Zusammenhängen essentiell. Soll beispielsweise herausgefunden werden, warum sich die Umsatzzahlen an bestimmten Standorten unbefriedigend entwickeln oder woran es liegt, dass eine Marketing-Kampagne exzellent funktioniert hat, dann spielen echte Kausalitäten eine große Rolle. Es reicht meist nicht zu wissen, dass der Umsatz an einem Standort nächstes Jahr vermutlich schlecht sein wird. Die Frage lautet, was der Grund dafür ist und was dagegen unternommen werden kann. Für den Speiseeisverkauf ist die Information, dass es eine hohe Korrelation zwischen Sonnenbränden und Speiseeisumsätzen gibt, dann nicht mehr hinreichend.
Die jeweilige analytische Vorgehensweise muss sich an der Zielsetzung des konkreten Projekts orientieren. Sollen Zusammenhänge lediglich beobachtet, und für die Vorhersage genutzt werden, reichen gut gewählte Trainings- und Testdatensätze. Der Testdatensatz hat dann hauptsächlich die Funktion sicherzustellen, dass der Algorithmus keine zufälligen Zusammenhänge im Trainingsdatensatz beobachtet hat, die es ausschließlich dort gibt.
Sollen aber kausale Zusammenhänge identifiziert werden, ist ein Hypothesen-gestützter Ansatz meist unumgänglich. Mittels Domänenwissen werden dabei Theorien aufgestellt und anschließend mit Hilfe der Daten getestet. Es wird dabei explizit nach Störfaktoren (Confounding Variables) und mehrschichtigen kausalen Zusammenhängen gesucht, um diese und ihren Effekt auf das eigentliche Ziel der Analyse zu verstehen. Für die Arbeit an solchen Kausalitäten haben Data Scientists ein immer größer werdendes Set an Werkzeugen wie Root Cause Analysis, Causal Discovery oder Causal Inference. Einige der bekanntesten Frameworks für Kausalitätsanalysen sind die CausalDiscoveryToolbox oder Microsofts DoWhy für Python sowie pcalg für R.
Suchen und Finden
Das schwierige, und oft verschleierte Verhältnis zwischen Korrelation und Kausalität klärt auch die Frage, warum sich Ernährungsstudien regelmäßig widersprechen. Die Antwort ist einfach: In solchen Studien wird zwar nach kausalen Zusammenhängen gesucht, aber es werden ausschließlich korrelative Analysen dafür genutzt. Noch dazu meist mit erschreckend kleinen Stichprobengrößen. Das erlaubt immer die gezielte Suche nach dem, was man letztlich finden will. Der Erkenntnisgewinn daraus ist ebenso gering wie der praktische Nutzen.
*Björn Heinen ist Senior Data Scientist bei INFORM. In dieser Rolle erweitert er bestehende Optimierungssysteme um Machine-Learning-Funktionalitäten. Darüber hinaus ist er beratend bei Industrie-Unternehmen tätig, um mittels fallspezifischer Data-Science-Lösungen vertiefte Erkenntnisse über die jeweiligen Geschäftsprozesse zu gewinnen.









Be the first to comment