
Frühzeitige Skalierungsentscheidungen können sich als Nachteil erweisen. Befolgen Sie diese Tipps, um sicherzustellen, dass das Sharding von Daten der Skalierbarkeit Ihrer Anwendung tatsächlich hilft, anstatt sie zu behindern. [...]

Neue SaaS-Startups denken selten darüber nach, wie sie ihre Anwendungen skalieren können. Sicher, sie stellen sich den Tag vor, an dem sie expandieren müssen, und sie bauen Wachstum in ihre Finanzpläne ein, aber sie konzipieren ihre Anwendungen selten von Anfang an für Skalierbarkeit. Stattdessen konzentrieren sie sich eher auf die Fertigstellung von Funktionen, die sie verkaufen können.
Der richtige Zeitpunkt, um über Skalierung nachzudenken, ist jedoch ganz am Anfang – bevor sich der erste Kunde für Ihren Dienst anmeldet. Wenn das Unternehmen eine Funktion nach der anderen ausrollt und sich weiterhin Kunden anmelden, wächst das Unternehmen. Wenn das Unternehmen wächst, wird die Skalierung zu einem wichtigen Punkt.
Die Notwendigkeit der Skalierung wird oft deutlich, wenn ein neuer SaaS-Dienst an die Grenzen seiner Ressourcenkapazität stößt, insbesondere bei der Kapazität der Datenzugriffsressourcen. Oft ist die Datenbank, unabhängig von der Technologie, zu klein, um den wachsenden Anforderungen gerecht zu werden und kann ab einem bestimmten Punkt nicht mehr erweitert werden.
Dieses Problem kann unabhängig von der verwendeten Datenbanktechnologie auftreten, und unabhängig von der Größe des Servers oder der sonstigen Infrastruktur, die Sie eingerichtet haben, um sich den Raum für Wachstum zu verschaffen. Früher oder später werden Sie auf Skalierungsprobleme stoßen.
Sobald sich die Skalierungsressourcengrenze abzeichnet und ernsthafte Skalierungsentscheidungen getroffen werden müssen, ist Data Sharding – die Aufteilung Ihrer Daten auf mehrere parallele Datenbanken, wobei jede Datenbank ein Segment Ihres Geschäfts enthält – oft eine der ersten Lösungen, die eingeführt wird, um die Skalierungsfähigkeit Ihrer Anwendung zu erweitern. Hierfür gibt es viele Gründe:
- Die Aufteilung Ihrer Daten in mehrere Segmente ist eine scheinbar einfache Lösung, um Probleme mit Datenressourcen zu lösen. Wenn eine Datenbank zu klein ist, um Ihren Datenverkehr zu bewältigen, versuchen wir es mit zwei, oder drei, oder vier!
- Sobald Sie Ihre Anwendungsdaten gesplittet haben, ist es scheinbar sehr einfach, die Skalierung mit demselben Ansatz fortzusetzen – wenn Ihr Datenverkehr wächst, fügen Sie einfach weitere parallele Datenbanken zu Ihrer Anwendung hinzu.
Schauen wir uns das Sharding genauer an und wie es verwendet wird, um erste Probleme bei der Skalierung von Datenbanken zu lösen.
Ein einfaches Sharding-Beispiel
Was genau ist Sharding? Ein typischer SaaS-Anwendungsfall beinhaltet, dass Kunden mit einer Anwendung kommunizieren, die dann auf Daten zurückgreift, die in einer Datenbank gespeichert sind. Mit zunehmender Anzahl von Kunden steigt die Belastung der Anwendung. Normalerweise ist es relativ einfach, die Kapazität der Anwendung zu erhöhen, indem man mehr Server hinzufügt, um die Last zu bewältigen. (Das hat natürlich seine Grenzen und ist eine separate Diskussion zu einem anderen Zeitpunkt wert).
Sobald Sie jedoch eine bestimmte Anzahl von Kunden erreichen, wird Ihre Skalierungsgrenze plötzlich zu Ihrer Datenbank. Ihre Datenbank kann zusätzliche Kunden nicht mehr effektiv verarbeiten, und Ihre Anwendung wird mit Verfügbarkeits-, Leistungs- und anderen Problemen konfrontiert. Dies wird in Abbildung 1 veranschaulicht.
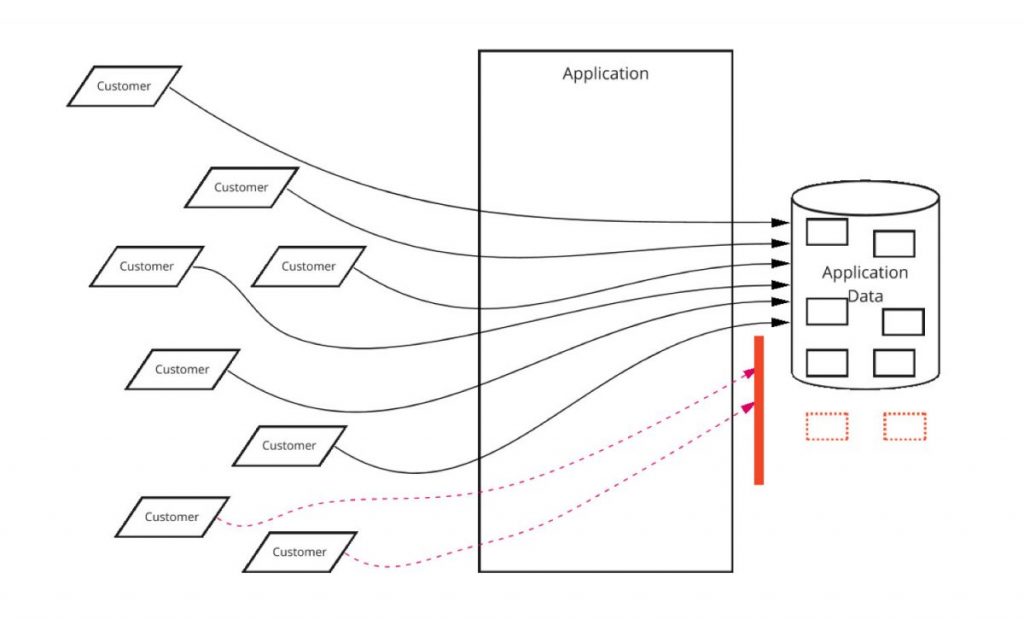
Sobald Ihre Datenbank eine bestimmte Größe und Kapazität erreicht hat, ist es schwierig (wenn nicht gar unmöglich), sie noch weiter zu vergrößern. Stattdessen können Sie sich dafür entscheiden, die Datenbank in mehrere parallele Datenbanken aufzuteilen und den Kundenstamm auf die verschiedenen Datenbanken aufzuteilen.
In Abbildung 2 haben wir die Kunden auf zwei separate Datenbanken aufgeteilt, und plötzlich können wir die zusätzlichen Kunden ohne Probleme verarbeiten. Jede Datenbank enthält alle Daten, die zur Unterstützung eines bestimmten Kunden erforderlich sind, aber die einzelnen Kunden sind auf verschiedene Datenbanken aufgeteilt.
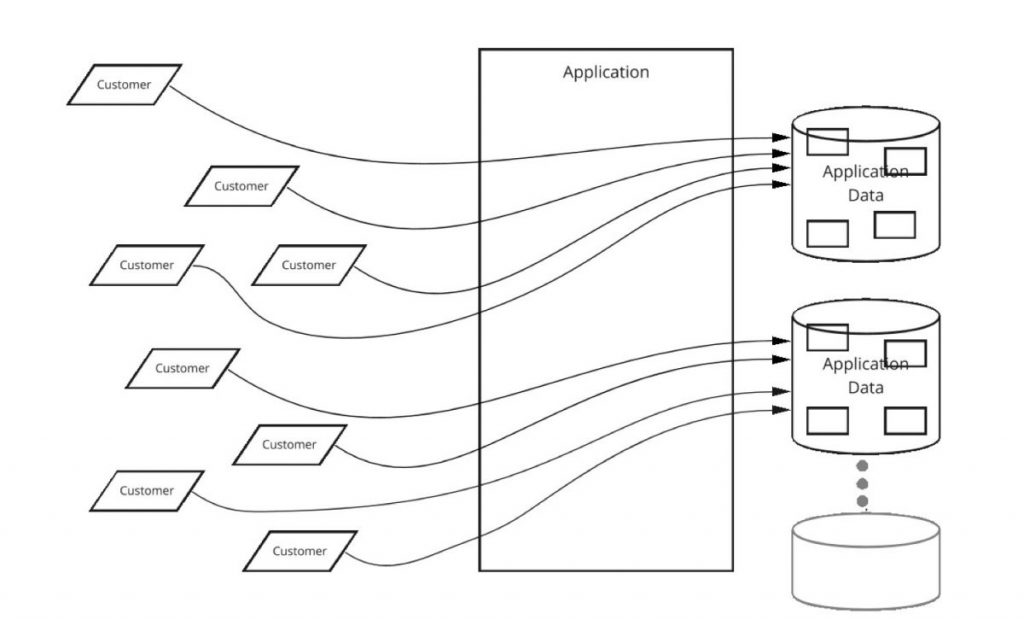
Wie kann man die Daten auf mehrere Datenbanken aufteilen und innerhalb der Anwendung wissen, welche Datenbank die Daten welchen Kunden enthält? Normalerweise wird ein Sharding-Schlüssel verwendet, um zu bestimmen, welche Datenbank einen bestimmten Datensatz enthält. Oft ist dieser Sharding-Schlüssel etwas wie eine Kunden-ID. Indem Sie einige Kunden-IDs einer Datenbank und andere Kunden-IDs einer anderen Datenbank zuordnen, können Sie alle Daten für einen bestimmten Kunden in einer einzigen Datenbank unterbringen. So wird für jeden Kunden eine einzige Datenbank für alle Kundenanfragen verwendet, und neue Kunden können in jeder vernünftigen Größenordnung zu neuen Datenbanken hinzugefügt werden.
Wo Sharding schief geht
Was ist also falsch an diesem Ansatz? Die Probleme beginnen, wenn Ihre Kunden zu wachsen beginnen. Je mehr Kunden die Anwendung nutzen, desto mehr Speicher und Ressourcen verbrauchen sie. Plötzlich wird die Kapazität eines Ihrer Shards überlastet, und Sie müssen einige Ihrer Kunden von einem Shard auf einen anderen (weniger stark belasteten) Shard verlagern. Sie müssen alle Daten dieser Kunden nehmen, sie auf einen neuen Shard kopieren und dann ihre Kunden-IDs auf den neuen Shard verweisen.
Dies ist kein trivialer Vorgang. Besonders dann nicht, wenn Sie dies ohne spürbare Ausfallzeiten für die Kunden bewerkstelligen wollen. Wie verschieben Sie tonnenweise Daten für einen bestimmten Kunden, ohne dass der Kunde während der Verschiebung auf die Anwendung zugreifen kann? Die Antwort beinhaltet in der Regel das Schreiben von benutzerdefinierten Werkzeugen. Dieses Tooling ist in der Regel nicht trivial zu schreiben und riskant in der Ausführung. Abbildung 3 veranschaulicht diesen Prozess, wenn ein „zu großer Kunde“ eine Datenbank überlastet und Sie ihn in eine andere, neuere Datenbank verschieben müssen.

Das nächste Problem, das auftritt, ist, wenn ein Kunde so groß wird, dass er einen ganzen Datenbank-Shard für sich allein benötigt. Was passiert in dieser Situation, wenn dieser Kunde etwas größer wird?
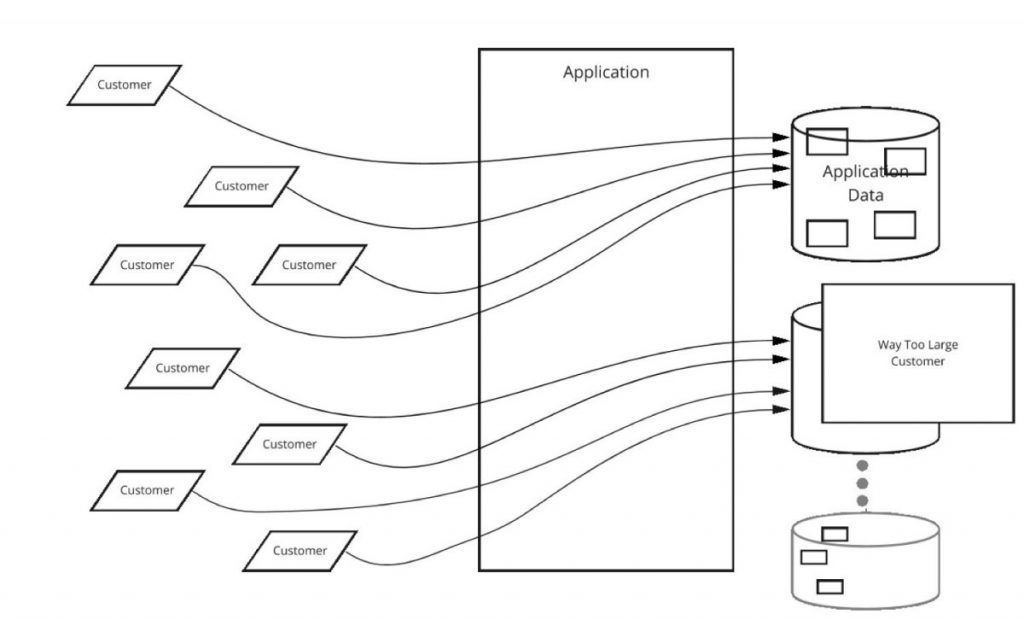
Plötzlich gibt es keinen Platz mehr, um diesen Kunden zu verschieben, und Sie haben eine weitere Skalierungsgrenze erreicht – eine Grenze, die Ihre aktuelle Sharding-Strategie einfach nicht bewältigen kann.
Repartitionierung, Rebalancing, verzerrte Nutzung, Sharding-übergreifendes Reporting und partitionierte Analysen sind weitere Probleme, die bewältigt werden müssen. Die Notwendigkeit, mit sich schnell ändernden Datensatzgrößen umzugehen und die Notwendigkeit, Daten zwischen Shards zu verschieben, sind jedoch die größten Herausforderungen bei einem hochwertigen Sharding-Mechanismus.
Sharding oder nicht Sharding?
Wenn Sie kein Sharding benötigen, lassen Sie es! Sie können andere Strategien verwenden, z. B. die Partitionierung von Daten nach Service und Funktion, anstatt sie in Shards aufzuteilen, um die Datenskalierung zu bewältigen.
Manchmal ist Sharding jedoch unvermeidbar. Wenn Sie also sharen müssen, sollten Sie Folgendes beachten:
- Richten Sie Ihre Shards ein, lange bevor Sie sie benötigen. Planen Sie den Bedarf an Sharding auf Basis einer optimistischen Skalierung ein und sharden Sie, lange bevor die tatsächliche Nutzung es erfordert.
- Wählen Sie Ihren Sharding-Schlüssel sorgfältig aus. Sie wollen, dass Ihre Shards unabhängig sind, aber auch gut ausbalanciert. Die Verwendung der Kunden-ID scheint eine gute Idee zu sein – sie ermöglicht es Ihnen, auf einfache Weise unabhängige Datensätze zu erstellen – aber die Kunden variieren stark in ihrer Größe, und der Ausgleich von Shards auf Basis der Kunden-ID kann problematisch sein. Es ist möglich, Shards auf Basis einer anderen gemeinsamen Ressource zu erstellen, aber die spezifische Antwort hängt stark von der Geschäftslogik und den Anforderungen Ihrer Anwendung ab.
- Entwickeln Sie Tools zur Verwaltung Ihrer Shards, bevor Sie das Sharding in die Produktion einführen. Sie werden die Tools viel früher benötigen, als Sie erwarten. Die Tools müssen in der Lage sein, schnell und effizient einzelne Sharding-Elemente (Kunden usw.) transparent von einem Shard zum anderen zu verschieben. Die Tools müssen in der Lage sein, mehrere Ressourcen während eines Skalierungsvorfalls schnell auszugleichen, und Sie benötigen Analysen, die Sie warnen, wenn die Shard-Größe ins Gegenteil umschlägt.
- Ziehen Sie ernsthaft in Betracht, Ihre Daten mit anderen Methoden aufzuteilen. Ziehen Sie in Erwägung, Ihre Daten innerhalb einzelner Dienste und Microservices zu speichern, anstatt in einem zentralen Datenspeicher. Je kleiner der Datensatz ist, desto geringer ist der Bedarf an Sharding und desto einfacher und effizienter ist es, Sharding bei Bedarf zu verwalten.
Die meisten modernen Anwendungen wachsen – ihre Nutzung, die Größe und Komplexität ihrer Daten, die Komplexität der Anwendung und die Anzahl der Mitarbeiter und die Größe der Organisation, die für die Verwaltung der Anwendung erforderlich sind. Es ist einfach, diese Wachstumsprobleme zu ignorieren, bis es zu spät ist, und dann eine schnelle und einfache Lösung für den unmittelbaren Bedarf zu verwenden. Aber wenn es um Data Sharding geht, sind Planung und gründliche Ausführung entscheidend, um sicherzustellen, dass diese architektonische Wahl eine Skalierungshilfe und keine Skalierungsbelastung ist.
*Lee Atchison ist ein anerkannter Vordenker im Bereich Cloud Computing und Anwendungsmodernisierung. Mit mehr als drei Jahrzehnten Erfahrung in den Bereichen Produktentwicklung, Architektur, Skalierung und Modernisierung hat Lee bei Amazon, Amazon Web Services (AWS), New Relic und anderen Unternehmen für moderne Anwendungen gearbeitet. Er wird in vielen Publikationen zitiert und war ein gefragter Redner auf der ganzen Welt. Lees neuestes Buch ist Architecting for Scale (O’Reilly Media). Sie können seine Bücher, Kurse, Artikel und Vorträge auf Twitter und LinkedIn nachlesen.









Be the first to comment