
Daten sind das wichtigste Rohmaterial für Analysen und Entscheidungen. Eine starke Data Supply Chain trägt zu einer Steigerung der Geschäftsergebnisse bei. [...]

Unternehmen haben heute mehr Daten zur Verfügung als je zuvor, und Datenarchitekten, Analysten und Data Scientists sind in allen Geschäftsbereichen immer häufiger anzutreffen. Doch während Unternehmen um qualifizierte Analysten kämpfen [engl.], um Daten für bessere Entscheidungen zu nutzen, kommen sie bei der Verbesserung der Data Supply Chain und der daraus resultierenden Datenqualität oft zu kurz. Ohne ein solides Management der Informationsversorgung leidet die Datenqualität häufig.
Schlechte Datenqualität wird als Hauptgrund dafür genannt, dass Initiativen ihr Ziel nicht erreichen – bis zu 60 Prozent der Geschäftsinitiativen [Gartner Whitepaper, engl.] scheitern aufgrund von Problemen mit der Datenqualität. Die Datenqualität wird zu einem noch dringlicheren Problem, wenn sich Unternehmen auf KI/ML-gestützte Entscheidungsfindung zubewegen. Wenn die Daten, die als Grundlage für KI-/ML-Modelle dienen, ungenau, unvollständig oder veraltet sind, werden die Modelle nicht die gewünschten Ergebnisse liefern.
Daten sind das wichtigste Rohmaterial für Analysen und Entscheidungsfindung. Deshalb fragt sich jede Führungskraft: „Wie können wir die Datenqualität verbessern, damit wir die bestmöglichen Entscheidungen treffen?“ Die Antwort lautet, die Ergebnisse der gesamten Data Supply Chain eines Unternehmens zu verbessern, um sicherzustellen, dass sie nicht zu einer Belastung für die Analysefähigkeiten wird.
Die Frage ist also: Wie können wir die Ergebnisse unserer Data Supply Chain verbessern?
- Verstehen der Auswirkungen von Daten auf der ersten und letzten Etappe
- Komplexität/Kosten der Supply Chain reduzieren
- Bessere Überwachung und Berichterstattung über die Datenqualität
Supply Chains setzen sich aus drei wesentlichen Elementen zusammen:
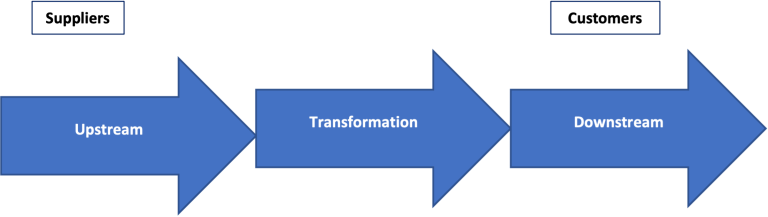
Auswirkungen auf die erste und letzte Etappe
Die Herausforderung der ersten und letzten Etappe erfordert eine ganzheitliche Betrachtung der Supply Chain, beginnend mit der Beschaffung der Daten (Upstream).
Die Dringlichkeit, Daten für die Analyse und Entscheidungsfindung zur Verfügung zu haben, veranlasst die Unternehmen dazu, mehr in die „letzte Etappe“ zu investieren, d. h. die Daten zum Kunden zu bringen (downstream). Im Fall der Data Supply Chain ist der Kunde natürlich eine interne Abteilung oder ein Team, das die Daten für Analysen, Berichte usw. benötigt. Die Herausforderung besteht darin, die Datenquelle von Anfang an korrekt zu erfassen und sicherzustellen, dass die Datenqualität beim Durchlaufen der Supply Chain nicht abnimmt.
Eine wichtige Kennzahl für das Supply Chain Management zur Bewertung der Leistung physischer Supply Chains ist OTIF – On-Time-In-Full. Dies ist zwar ein seltsames Akronym, aber die Verbesserung dieses Wertes hat dramatische Auswirkungen, da er sich direkt auf den Endkunden und seine Fähigkeit, seine Arbeit zu erledigen, bezieht.
Wenn Sie zum Beispiel 10 Attribute benötigen, um eine Kundenzufriedenheitsbewertung zu erstellen, aber nur 9 verfügbar sind, kann die Berechnung nicht durchgeführt werden. Die Verwendung einer Kennzahl, die sich auf die Auswirkungen der Datenqualität und -verfügbarkeit auf nachgelagerte Prozesse konzentriert, kann dazu beitragen, das Bewusstsein der Organisation zu schärfen.
Empfohlener Aktionsplan: Erstellen Sie eine Karte der Supply Chain Ihrer Daten.
Das Konzept der Supply Chain Visibility und der Beschaffung gilt für die Supply Chain von Daten ebenso wie für das Management der physischen Supply Chain. Das Verständnis der Datenquellen, der stattfindenden Transformationsaktivitäten und der „Kundenvorlaufzeit“ hilft Unternehmen, Risiken zu erkennen und zu mindern. Die Einführung von Kennzahlen zur Bewertung, wie gut das Unternehmen die Kundenbedürfnisse erfüllt, hilft, den Fokus auf Verbesserungen zu schärfen.
Komplexität/Kosten der Supply Chain
Die Komplexität der Supply Chain beschreibt das Netzwerk von Fähigkeiten, die zur Erfüllung nachgelagerter Anforderungen erforderlich sind. Je größer die Anzahl der benötigten Lieferanten, Geschäftsfunktionen und Händler ist, desto größer ist die Komplexität.
Jedes zusätzliche Element in der Supply Chain erhöht die Komplexität, und mehr Komplexität trägt zu einer höheren Variabilität bei. Variabilität ist eine große Herausforderung [engl.] für die Qualität. In physischen Supply Chains versuchen Unternehmen, die vorgelagerte Komplexität zu reduzieren. In der Daten-Supply Chain gibt es eine Vielzahl interner und externer Datenquellen (von Datenbrokern, sozialen Medien/Sentiment-Analysen usw.), und genau wie in einer physischen Supply Chain trägt die Reduzierung der Komplexität in der Data Supply Chain zur Verbesserung der Gesamtqualität bei.
Inwiefern kann die Verringerung der Komplexität die Qualität verbessern? Weniger Systeme bedeuten weniger Datenumwandlungen, was die Verfügbarkeit und Genauigkeit der Daten erhöht.
Empfohlener Aktionsplan: Inventarisierung der für die nachgelagerte Nutzung verfügbaren Daten und Zuordnung zum Quellsystem (intern oder extern).
Häufig werden gemeinsame Attribute in mehr als einem System erstellt, was die Komplexität erhöht. Wählen Sie für jedes Datenelement ein einziges System für die nachgelagerte Nutzung aus und erstellen Sie ein „System of Record“ (SOR) mit dem Ziel, Daten aus so wenigen Systemen wie möglich zu erhalten.
Überwachung und Berichterstattung
Die Datenqualität sollte heute für fast jedes Unternehmen ein wichtiger Leistungsindikator sein. Die Qualität der Ergebnisse hängt von der Qualität des Inputs ab. Denken Sie an jedes gute Restaurant, in dem Sie jemals gegessen haben, und was es ausgemacht hat. Sicherlich spielen die Gesellschaft und das Ambiente des Lokals eine Rolle, doch die Qualität der Zutaten wirkt sich direkt auf das Ergebnis aus – frisch gefangene Meeresfrüchte sind immer besser als tiefgekühlte.
Die Methoden und die Frequenz der Bewertung der Datenqualität variieren oft innerhalb eines Unternehmens. Verschiedene Funktionen in einem Unternehmen können unterschiedliche Methoden zur Bewertung der Qualität anwenden; die Buchhaltung kann zum Beispiel strenger sein als das Marketing.
Doch warum sollten die verschiedenen Funktionen unterschiedlich bewertet werden? Gute Entscheidungen beruhen auf qualitativ hochwertigen Daten, und sollte nicht jede Funktion die bestmöglichen Entscheidungen treffen?
Empfohlener Aktionsplan: Legen Sie eine gemeinsame Formel für die Messung der Datenqualität fest und verwenden Sie die Messung einheitlich für alle Funktionen (Datenqualitäts-Score [engl.]).
Die Menge der zu bewertenden Daten erfordert Stichproben und Schätzungen, und der Ansatz sollte einheitlich sein. Ein Ansatz kann darin bestehen, eine Stichprobe von 100 Datensätzen zu nehmen, jeden einzelnen zu überprüfen und eventuelle Fehler zu identifizieren und dann die fehlerfreien Datensätze zu zählen, um den Prozentsatz der korrekt erstellten Daten zu ermitteln.
Die Data Supply Chain ist für viele Unternehmen ein neues und sich entwickelndes Konzept. Die Suche und Bindung von Talenten, die zur Verbesserung der Ergebnisse der Data Supply Chain beitragen, ist für den Erfolgsfaktor eines Unternehmens entscheidend. Sicherlich gibt es Unterschiede zwischen materiellen und immateriellen Produkten, doch viele der Konzepte und Tools aus der physischen Welt lassen sich auch auf Daten anwenden, und das Ergebnis wird ebenso wirkungsvoll sein wie die Verbesserung physischer Supply Chains.
Zögern Sie also nicht, den Anfang zu machen.
*Dave Angelow ist Unternehmensberater und außerordentlicher Professor an der McCoy School of Business der Texas State University. Darüber hinaus bekleidete er Führungspositionen in den Bereichen IT, Betrieb und Geschäftsentwicklung bei verschiedenen anderen Unternehmen (Ernst & Young, Applied Materials, Dell, Fiskars Brands, AT&T und BlueYonder/i2 Technologies).









Highly recommend this Allmachines if you’re looking for serious equipment options. I explored their powerful forage headers and got helpful details. There’s also a section on forage harvesters that’s worth a look. For unique applications, their specialty crop harvesters category stands out. Finally, their range of attachments is very extensive.