
Da Unternehmen vermehrt auf geschäftskritische IT-Dienste angewiesen sind, sind Infrastruktur und Anwendungen nach Meinung von Rubrik zu wichtigen strategischen Imperativen geworden. Der junge Anbieter von Cloud Data Management erklärt Kennzahlen und Kriterien der Datensicherung. [...]
„Ausfallzeiten und Datenverluste können enorme geschäftliche und finanzielle Auswirkungen haben, die mit einer effektiven Datensicherungsstrategie zwingend minimiert werden müssen“, erklärt Roland Stritt, Director Channels EMEA bei Rubrik. „Bei der Planung einer Datensicherungsstrategie oder eines Disaster-Recovery-Plans sind mehrere Kriterien bezüglich der geschäftlichen Auswirkungen verschiedener Anwendungen und Workloads zu berücksichtigen.“
Eine Business-Impact-Analyse (BIA) kann helfen, die Auswirkungen und Konsequenzen einer Unterbrechung des Geschäftsbetriebs sowohl finanzieller als auch nichtfinanzieller Art zu beurteilen und abzuwägen. Diese Ergebnisse können Unternehmen dabei helfen, ihre Verfügbarkeits–Service-Level-Agreements (SLAs) oder den vom Kunden erwarteten Service-Level zu bestimmen. Meistens werden mehrere SLAs definiert, die den verschiedenen Stufen der Kritikalität entsprechen, die mithilfe der BIA ermittelt wurden.
Beispielsweise werden die folgenden SLAs häufig verwendet:
- 99 Prozent oder „Two 9s“ entsprechen 3 Tagen 15 Stunden und 36 Minuten Ausfallzeit pro Jahr.
- 99,9 Prozent oder „Three 9s“ entsprechen 8 Stunden 45 Minuten und 36 Sekunden Ausfallzeit pro Jahr.
- 99,99 Prozent oder „Four 9s“ entsprechen 52 Minuten und 34 Sekunden Ausfallzeit pro Jahr.
Verfügbarkeits-SLAs werden dann von der IT-Abteilung oder dem Dienstanbieter in vertretbare Datenverluste und ungeplante Ausfallzeiten umgerechnet. Die Recovery Point Objective (RPO) und Recovery Time Objective (RTO) sind zwei der wichtigsten Konstrukte eines SLAs und repräsentieren diese Ziele.
Recovery Point Objective
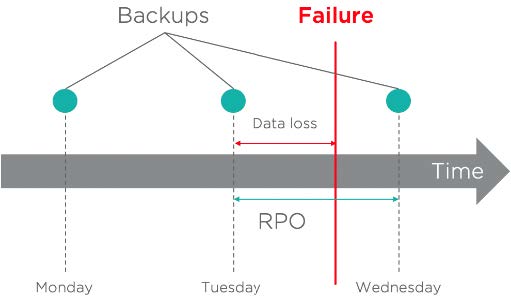
Die RPO stellt die maximale Datenmenge dar, die ein Unternehmen sich leisten kann, zu verlieren. Um genauer zu sein, beschreibt die RPO den Zeitpunkt, zu dem sich das Unternehmen bei der Wiederherstellung den größten Rückstand leisten kann. Aus datenschutzrechtlicher Sicht entspricht dies in der Regel der Häufigkeit, mit der Daten gesichert oder repliziert werden müssen. Diese kann in Tagen, Stunden, Minuten oder sogar Sekunden ausgedrückt werden.
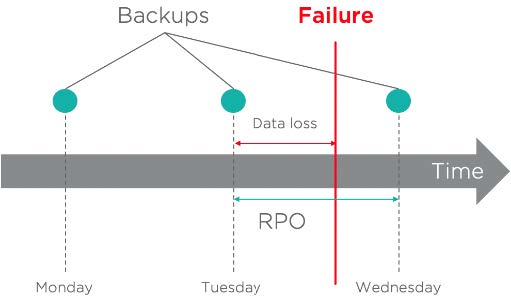
Im folgenden Beispiel beträgt die vereinbarte Verfügbarkeits-SLA 99 Prozent, was etwas mehr als 3,5 Tage tolerierter Ausfallzeit entspricht. Da das SLA sowohl die RPO als auch die RTO umfasst, muss die Summe der beiden kleiner als 3,5 Tage sein. Um diesem SLA gerecht zu werden, wurde eine RTO und eine RPO von 24 Stunden definiert. Es ist möglich, den ausgefallenen Workload aus dem letzten Backup wiederherzustellen, das weniger als 24 Stunden alt ist. Daten, die zwischen der letzten Sicherung und dem Fehlerereignis erstellt oder geändert wurden, gehen verloren. Da es sich jedoch um Daten im Wert von weniger als 24 Stunden handelt, wird die Recovery Point Objective erreicht.
Im folgenden Beispiel beträgt die definierte RPO noch 24 Stunden. Am Mittwoch ist ein Fehler aufgetreten, aber die Daten konnten nicht aus dem letzten Backup, das am Dienstagabend erstellt wurde, wiederhergestellt werden. Der Administrator muss die Arbeitslast aus dem Backup des Vortages wiederherstellen, was bedeutet, dass mehr als 24 Stunden Daten verloren gegangen sind. Das Ziel wird in diesem Fall nicht erreicht.
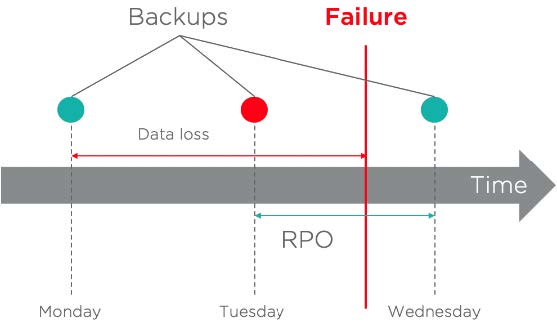
Um dieses Risiko zu minimieren, könnte die Sicherungshäufigkeit so angepasst werden, dass sie häufiger auftritt, während eine RPO von 24 Stunden eingehalten wird.
Die meisten Workloads, Anwendungen oder Datensätze mit einer niedrigen bis durchschnittlichen Kritikalität haben eine SLA von 99 Prozent oder weniger und eine RPO von 24 Stunden oder mehr. Es ist sehr häufig, dass solche Workloads ein- bis zweimal täglich gesichert werden.
Für kritischere Workloads mit einer SLA von 99,9 Prozent oder mehr ist es notwendig, die RPO auf wenige Stunden, ja sogar Minuten oder Sekunden zu reduzieren, um konform zu sein.
Recovery Time Objective
Die RTO entspricht der maximalen Zeit, in der ein ausgefallener Workload wiederhergestellt werden muss.
Einige Anwendungen und Dienste können jedoch einige Zeit in Anspruch nehmen, oder Workloads können nach der Wiederherstellung zunächst in einem verschlechterten Modus neu gestartet werden. In solchen Fällen kommt die zusätzliche Zeit, die benötigt wird, bis die wiederhergestellten Workloads einsatzbereit sind, zur RTO hinzu und wird als Work Recovery Time (WRT) bezeichnet. Die Addition von RTO und WRT definiert die maximal tolerierbare Ausfallzeit, bezeichnet als Maximum Tolerable Downtime (MTD).
In der folgenden Abbildung beträgt das vereinbarte SLA noch 99 Prozent und die RTO 24 Stunden. Der fehlerhafte Workload wird in weniger als 24 Stunden wiederhergestellt. Das Ziel der Wiederherstellungszeit wird erreicht.
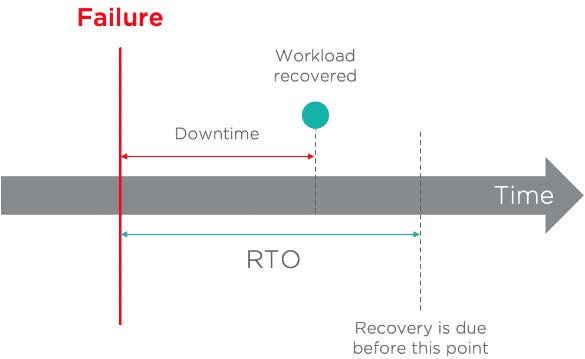
Im Gegenteil dazu wird in der nächsten Abbildung das Ziel nicht erreicht, da die Wiederherstellung des ausgefallenen Workloads länger dauerte als die definierte RTO.
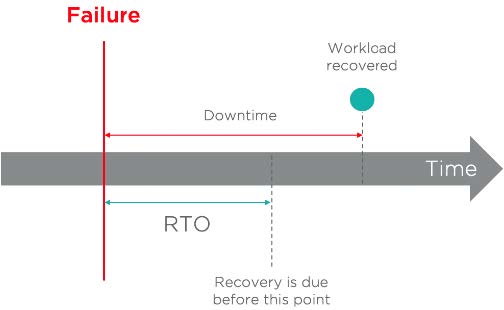
Es gibt mehrere Faktoren, die die Wiederherstellungszeiten beeinflussen, einschließlich:
- Umfang des Fehlers. Ausfälle können auf verschiedenen Ebenen einer Infrastruktur auftreten. Es ist schneller und einfacher, einzelne Workload-Ausfälle zu beheben, als beispielsweise einen Speicher-Array-Ausfall oder einen kompletten Rechenzentrumsausfall. Darüber hinaus gibt es mehrere Möglichkeiten, die Situation zu überwinden, wenn kritische Hardware wie ein Speicher-Array ausfällt. Das Array selbst kann repariert oder ersetzt werden, oder es kann ein Failover auf eine Disaster-Recovery-Infrastruktur ausgelöst werden. Letzteres ermöglicht wesentlich kürzere Wiederherstellungszeiten als Ersteres.
- Menge und Art der wiederherzustellenden Daten. Im Allgemeinen gilt: Je größer die wiederherzustellende Datenmenge, desto länger ist die Wiederherstellung. Aber gleichzeitig dauert es in der Regel kürzer, einige wenige Dateien wiederherzustellen, als einen ganzen Computer oder eine große Datenbank.
- Backupspeicherleistung. Oftmals ist Backup-Speicher, auch als Sekundärspeicher bezeichnet, kostengünstiger als Produktionsspeicher und bietet nicht die gleiche Leistung. Die Wiederherstellungszeiten hängen davon ab, was der Backup-Speicher liefern kann.
- Netzwerkperformance. In den meisten Fällen laufen Datenübertragungen für Wiederherstellungsvorgänge über das Netzwerk. Unternehmen, die Ethernet-Netzwerke mit 10 Gbit/s (oder mehr) für Backup- und Wiederherstellungszwecke verwenden, profitieren von mehr Bandbreite, was wiederum dazu beiträgt, die Wiederherstellungszeiten zu verkürzen. Wenn Daten über ein von verschiedenen Streams gemeinsam genutztes Netzwerk wiederhergestellt werden müssen, kann die Wiederherstellung aufgrund der geringeren verfügbaren Bandbreite länger dauern.
RPO und RTO: Der Ansatz von Rubrik
Rubrik setzt sich seit langem dafür ein, die Datensicherung einfach, sicher, zuverlässig und schnell zu gestalten. Damit Unternehmen ihre RPOs verbessern können, bietet Rubrik Cloud Data Management (CDM) eine Reihe von Technologien und Funktionen, die helfen, Backup-Fenster zu reduzieren und die Backup-Frequenz zu erhöhen:
- Ingestion zur Optimierung der Speicherung. Rubrik bietet ein skalierbares und verteiltes Dateisystem, das sich über alle Festplatten im Cluster erstreckt. In Kombination mit der Löschkodierung ist die Aufnahmeleistung vergleichbar mit der von Flash-Speichern.
- Parallele Ingestion. Rubrik-Cluster bestehen aus mindestens drei bis vier Knoten, und die Lösung skaliert, indem sie weitere Knoten zu demselben Cluster hinzufügt, in dem alles verteilt ist. Jeder Knoten im Cluster kann mehrere Workloads gleichzeitig sichern. Je größer der Cluster, desto mehr Daten können parallel aufgenommen werden und desto kürzer ist das Backup-Fenster.
- Inkrementell. Sobald das erste vollständige Backup abgeschlossen ist, sichert Rubrik nur noch neue und geänderte Daten. Dies trägt auch zu kürzeren Backup-Fenstern bei und reduziert den erforderlichen Bandbreitenverbrauch des Netzwerks.
Rubrik unterstützt die erweiterte Integration mit Microsoft SQL Server und Oracle. Diese Workloads werden auf Anwendungsebene mit Hilfe des Rubrik Backup Service (RBS) gesichert, der auf den entsprechenden Servern eingesetzt wird. Dies ermöglicht eine periodische anwendungskonsistente Sicherung einzelner oder aller Datenbanken, aber auch eine Sicherung von Transaktionsprotokollen für SQL Server und Archivprotokollen für Oracle.
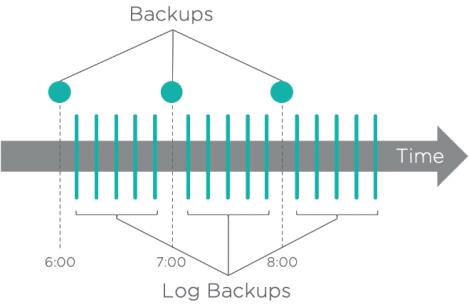
Die erweiterte Protokollverarbeitung ermöglicht einen viel häufigeren Point-in-Time-Backup der kritischsten Datenbanken, bei denen die RPO viel geringer ist, in der Regel bis hinunter auf wenige Minuten. Eine solche Verarbeitung kann als nahezu kontinuierliche Datensicherung bezeichnet werden. Die folgende Abbildung zeigt ein Beispiel, bei dem anwendungskonsistente Backups jede Stunde und Log-Sicherungen alle zehn Minuten durchgeführt werden.
Wenn eine Multi-Terabyte-VM, virtuelle Festplatte oder Datenbank wiederhergestellt werden muss, dauert es in der Regel sehr lange, bis sie wiederhergestellt und in der Produktionsumgebung verfügbar ist. Um dieses Problem zu lösen, bietet Rubrik diese Technologien an:
- Instant Recovery. Speziell für vSphere und Hyper-V-VM-Wiederherstellung kann diese Funktion ein VM-Image direkt aus den auf der Rubrik-Appliance gespeicherten Backup-Daten veröffentlichen und aktivieren. Diese Art der Wiederherstellung ist destruktiv, d.h. das neue VM-Objekt, das von Rubrik gebootet wurde, ersetzt das ursprüngliche. Instant Recovery eliminiert herkömmliche Wiederherstellungszeiten und bringt nahezu Null RTO auf die kritischsten VMs.
- Live Mount. Ähnlich wie bei der Sofortwiederherstellung (Instant Recovery) kann Live Mount ein komplettes VM-Image, ein einzelnes VMDK und eine einzelne SQL- oder Oracle-Datenbank von der Rubrik-Appliance zurück in die Produktionsumgebung veröffentlichen. Wenn ein Live-Mount ausgeführt wird, wird der wiederhergestellte Workload als neues Objekt veröffentlicht und nicht überschrieben.
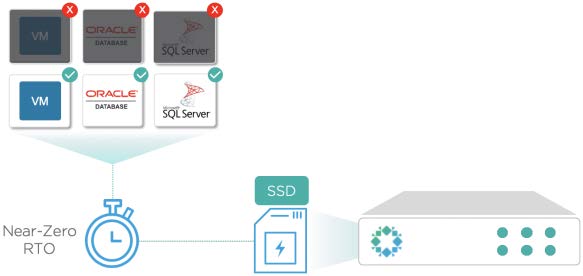
- Fast Storage. Jedes Rubrik-Cluster bietet genügend Speicherleistung, um mehrere gleichzeitige Live Mounts oder Instant Recoveries zu ermöglichen. Insbesondere verfügt jeder Knoten über ein Flash-Laufwerk, das zum Cachen von Daten verwendet wird, die von Instant Recovery und Live Mount veröffentlicht werden.
- Fast Networking. Rubrik Appliances werden mit schnellen und modernen Netzwerkschnittstellenkarten (10 Gbit/s und mehr) in jedem Knoten geliefert. Dies ergänzt den schnellen Speicher und die Live-Mount-Technologien, um die schnellstmögliche Wiederherstellung zu ermöglichen.
Fazit
„Wenn RPOs und RTOs für alle Workloads und Anwendungen sowie für die Kosten von Ausfallzeiten für ein bestimmtes Unternehmen bekannt sind, können die richtigen Entscheidungen getroffen werden, um Daten angemessen zu sichern“, so Roland Stritt von Rubrik. „Die IT-Abteilung hat die Aufgabe, die richtigen Technologien auszuwählen und eine geeignete Strategie rund um Datensicherung und Disaster Recovery zu entwickeln.“









Be the first to comment