
Im Internet der Dinge geht es vor allem um die Verarbeitung riesiger Datenmengen, die von verteilten und vernetzten Geräten im Rechenzentrum eingehen. Diese Herausforderungen kann nach Ansicht von Ververica das Streaming Processing zuverlässig bewältigen. [...]
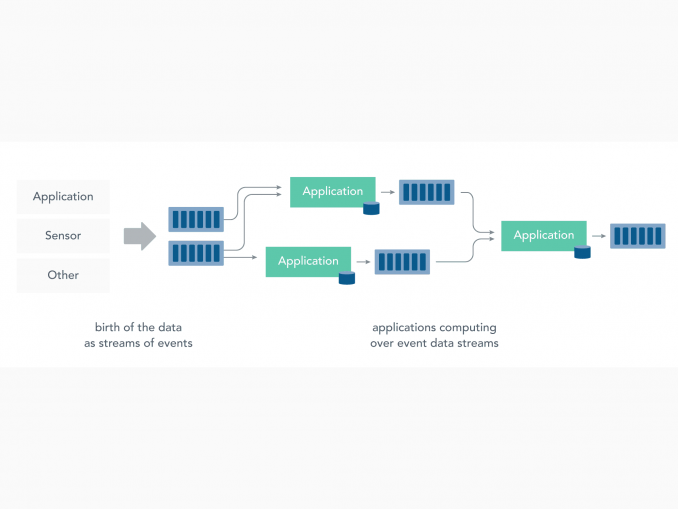
Auf der diesjährigen Hannover Messe kommt man an den Trendthemen Digitalisierung, 5G und Vernetzung nicht vorbei. Sie sind Begleiter der zentralen Entwicklung, bei der Kommunikationstechnologie und Informationstechnologie zunehmend verschmelzen: das Internet der Dinge (IoT) bzw. Industrial Internet of Things (IIoT) – oft auch gleichgesetzt mit Industrie 4.0. Ververica (ehemals Data Artisans) beobachtet diese Entwicklung vor allem aus Sicht der steigenden Anforderungen an die Datenverarbeitung. Hierbei ergeben sich nach Meinung von Ververica drei grundlegende Herausforderungen:
- IoT-Geräte produzieren sehr viel mehr Daten als Menschen an Arbeitsplätzen. Dies macht herkömmliche Datenbanken für den Umgang mit diesen großen Mengen an kontinuierlich von Edge-Geräten erzeugten Daten ineffizient.
- IoT-Anwender erwarten Echtzeitinformationen, auf die sie sofort reagieren können. Daher sind ETL-Pipelines oder Batch-Datenoperationen nicht optimal für eine Echtzeitantwortfähigkeit.
- Die Konnektivität ist in der IoT-Industrie nie vollständig gewährleistet, insbesondere, wenn Daten von Edge-Geräten über Mobilfunknetze gesendet werden.
Freeport Metrics hat bereits an mehreren Daten-Streaming-Projekten in der IoT-Branche gearbeitet. Hierzu zählen beispielsweise der Aufbau einer Überwachungs- und Abrechnungsplattform für Solarenergie und die Optimierung der Datenverarbeitung in Windparks. Kürzlich hat das Unternehmen eine groß angelegte RFID-Asset-Tracking-Plattform für Echtzeitverarbeitung entwickelt, die Apache Flink als zugrundeliegendes Stream-Verarbeitungs-Framework verwendet.
Nachfolgend sind sieben Gründe aufgelistet, die nach Ansicht von Ververica erklären, warum die Stream-Verarbeitung mit Apache Flink im Internet der Dinge ein erfolgsversprechender Ansatz ist.
1. Echtzeit-Datenverarbeitung ist ein entscheidender Faktor
Die IoT-Industrie verlangt sofortige Informationen und Maßnahmen bei jeder Geräteaktivität. Ein typisches Beispiel wäre, dass es windig ist, aber eine bestimmte Windturbine keine Energie produziert. Ein anderer Fall wäre, dass ein kostbares Gut aus einem unbekannten Grund das Werksgelände verlässt. In beiden Fällen müssen die betroffenen Unternehmen diese Informationen sofort erfassen und darauf zugreifen können.
Die Verarbeitung von Datenströmen anstelle von Batches ermöglicht es, Berechnungen sofort bei Verfügbarkeit von Daten auszulösen, zeitnahe Warnungen zu setzen oder Ereignismuster kontinuierlich zu erkennen. Darüber hinaus wirkt sich die sofortige Verarbeitung der erzeugten Daten positiv auf die Performance aus. So sind beispielsweise keine Berechnungen erforderlich, wenn kein neues Ereignis eingetreten ist, was bedeutet, dass nicht der gesamte Datensatz regelmäßig neu berechnet werden muss, um neue Ergebnisse zu erhalten.
2. Die Ereigniszeit ist die richtige Art der Datenbestellung in der IoT-Industrie
Wenn Daten von IoT-Geräten über ein Mobilfunknetz übertragen werden, ist es wichtig, Latenzzeiten und Netzwerkausfälle zu berücksichtigen. Selbst wenn über eine stabilere Verbindung gesendet wird, lassen sich die Gesetze der Physik nicht umgehen, und die Entfernung der IoT-Geräte vom Rechenzentrum erhöht zwangsläufig die Latenzzeit. Ein Beispiel wäre ein Maschinen- oder Automobilbauteil, das sich durch eine Produktionslinie mit daran angeschlossenen Sensoren bewegt. Es gibt keine Garantie dafür, dass die Messwerte dieser Sensoren in der Reihenfolge ihrer Erfassung über das Netzwerk ankommen.
Meistens ist es beim Umgang mit Daten von IoT-Geräten sinnvoll, Ereignisse nach dem Zeitpunkt ihres Auftretens, und nicht nach dem Zeitpunkt ihrer Ankunft im Rechenzentrum zu verarbeiten. Aus diesem Grund ist die Unterstützung der Ereigniszeit ein Muss bei der Auswahl eines Datenverarbeitungs-Frameworks.
3. Tools für den Umgang mit unordentlichen Daten
Die Datenvorverarbeitung am Edge ist in der Regel der herausforderndste Teil des Prozesses. Dies ist noch schwieriger, wenn die Quelle nicht vollständig kontrolliert werden kann, wie es in der IoT-Welt oft der Fall ist.
Die Stream-Verarbeitung repariert unvollständige Daten nicht, aber sie bietet einige nützliche Tools. Hierzu zählt insbesondere Windowing, ein Konzept, bei dem Elemente eines unbegrenzten Stroms in endliche Mengen gruppiert werden, basierend auf Dimensionen wie Zeit oder Elementanzahl für die weitere Verarbeitung. Wenn die Daten verrauscht sind (z.B. analoge Sensoren, GPS), lässt sich eine eigene Window-Processing-Funktion schreiben.
Freeport Metrics arbeitete mit Leistungsmessgeräten, die Daten schnell senden, aber aufgrund des Modbus-Protokolls störanfällig sind und daher erst am Ende des Tages präzise Daten-Batch-Dateien erzeugen. In diesem Fall kann auf Modbus-Daten zurückgegriffen werden, um ungefähre Live-Statistiken zu berechnen, die dem Endbenutzer angezeigt werden. Die Modbus-Daten werden später durch Batch-Input ersetzt, damit sie für eine genaue Abrechnung verwendet werden können. Dies kann durch das Schreiben eines Triggers erreicht werden, der Teilergebnisse liefert, wenn neue Daten eintreffen und das Fenster schließt, wenn es Chargendaten erhält.
Manchmal ist es unmöglich zu bestimmen, ob alle Daten angekommen sind. In diesem Fall würden Fenster nach einem heuristischen Wasserzeichen ausgelöst, das empirisch berechnet werden kann oder es ist von einem abgelaufenen Timeout auszugehen. Flink ermöglicht es auch, die zulässige Verspätung von Elementen festzulegen und stellt seitliche Ausgaben zur Verfügung, um später auftretende Ereignisse zu behandeln.
4. Segmentierung ermöglicht Parallelverarbeitung
Häufig sind verschiedene Benutzer eines IoT-Systems an Berechnungen interessiert, die nur an einer Teilmenge von Daten durchgeführt werden. Ein Beispiel wäre eine Plattform, die es Katzenbesitzern ermöglicht, zu verfolgen, wo ihre geliebten Haustiere unterwegs sind. Jeder Besitzer benötigt nur Daten vom GPS-Tracker seiner eigenen Katze. Flink stellt zu diesem Zweck das Konzept der Gruppierung nach Schlüssel vor. Sobald ein Stream partitioniert ist, kann er parallel verarbeitet werden, so dass er sich horizontal vergrößern lässt. Natürlich muss ein Schlüssel nicht an ein einzelnes IoT-Gerät oder einen Standort gebunden sein. Im Falle des Flottenmanagements lassen sich beispielsweise verschiedene Signale, die sich auf ein einzelnes Fahrzeug beziehen, gruppieren (z.B. GPS, Hardwaresensoren, Kennzeichenerfassung an Parktoren).
Lösungsmöglichkeiten verspricht hier Ververica Streaming Ledger, verfügbar in der River Edition der Ververica-Plattform. Streaming Ledger ermöglicht verteilte Transaktionen zwischen parallelen Streams über gemeinsame Zustände und Tabellen.
5. Der lokale Zustand ist entscheidend für die Performance
Während jeder Programmierer wissen sollte, dass sich die Latenzzahlen aufgrund von Fortschritten in Hardware und Infrastruktur jedes Jahr ändern, bleiben einige Grundregeln konstant:
- Je näher die Daten liegen, desto schneller können sie bearbeitet werden.
- Festplatten-I/O ist nicht gut für die Performance.
Mit Apache Flink lassen sich Daten genau dort aufbewahren, wo Berechnungen mit dem lokalen Status durchgeführt werden. Noch wichtiger ist, dass der Zustand durch leichtes Checkpointing, das die I/O begrenzt, fehlertolerant ist. Anwender sollten sich nicht täuschen lassen, dass der lokale Zustand nur eine weitere Form des schreibgeschützten lokalen Cache ist. Es funktioniert wirklich, wenn das System mit Ereignisdaten aktualisiert wird. Beispielsweise können historische Werte von Sensormesswerten im lokalen Zustand gespeichert und mit neuen Daten aktualisiert werden, um Live-Statistiken zu berechnen. Einige Experten stellen sogar die Notwendigkeit einer weiteren Persistenzschicht in Frage und schlagen vor, Flink als Single-Source-of-Truth (SSoT) zu verwenden.
6. Flink liebt Messaging
In Zusammenhang mit Streaming geht es oft auch um Messaging-Systeme wie Apache Kafka, AWS Kinesis oder RabbitMQ, die hoch skalierbar und zuverlässig sind für die Aufnahme großer Mengen von Ereignissen. Flink bietet erstklassige Unterstützung für alle drei, sowohl als Produzenten als auch als Konsumenten und macht gleichzeitig seinen verteilten Charakter mit charakteristischen leistungssteigernden Funktionen wie Partitionierung oder Sharding deutlich. Die End-to-End-Verarbeitung wird auch von Flink auf diese Systeme ausgedehnt, wenn sie als Konsumenten genutzt werden, insofern es der Anwendungsfall erfordert.
7. Daten-Streaming ist konzeptionell einfach, sobald man sich daran gewöhnt hat
Last but not least, fühlt sich ein Daten-Streaming-Ansatz einfach naheliegend an. Es erfordert zwar eine steile Lernkurve für das Team, sich an die korrekte Verwaltung des Zustands in Flink anzupassen oder mit der Bedienerparallelität zu arbeiten. Sobald man sich daran gewöhnt hat, kann man sich auf die Kernlogik der Anwendung konzentrieren, da der Großteil der groben Arbeit vom Framework erledigt wird.
Freeport Metrics hat Ähnliches erlebt, als das Unternehmen von der Batch-Verarbeitung zur Stream-Verarbeitung mit Apache Flink übergegangen ist. Gleiches gilt bei den meisten technologischen Übergängen zu neueren, aktualisierten Frameworks oder Plattformen. Irgendwann wird klar, dass man das richtige Werkzeug für einen bestimmten Job gefunden hat und es stellt sich die Frage, wie es zuvor überhaupt ohne ging.
Die oben genannten Beobachtungen legen nach Meinung von Ververica den Schluss nahe, dass die Datenverarbeitung in der IoT-Industrie wirklich von der Einführung eines Stream-Processing-Frameworks wie Apache Flink profitieren kann. Die Funktionen, Konnektoren, Fehlertoleranz und Zuverlässigkeit von Flink bilden einen der besten Rahmen, um die Herausforderungen zu meistern, mit denen IoT-Unternehmen konfrontiert sind, wenn sie die riesige Menge an Daten bewältigen müssen, die es jeden Tag, jede Minute oder Sekunde in Echtzeit zu verarbeiten gilt.









Be the first to comment