
Valide, brauchbare Daten sind eine Voraussetzung für erfolgreiches Machine Learning. Fünf Tipps, damit Projekte nicht an der Datenqualität scheitern. [...]

Maschinelles Lernen (ML) basiert auf der statistischen Verarbeitung großer Datenmengen. Das System erkennt zwischen den Datensätzen Zusammenhänge sowie Muster und extrapoliert sie in Form eines Algorithmus. Dabei gilt: Je besser die Datenqualität, desto höher die Vorhersagegüte des Datenmodells. Man benötigt daher einer geeigneten Aufbereitung der Rohdaten – beispielsweise in Hinblick auf fehlende und falsche Angaben sowie Ausreißer, um aus den vorhandenen Daten den maximalen Nutzen zu ziehen.
Mehr noch: Da viele Modelle nur numerische Formate verarbeiten können, ist eine Bereinigung der Daten, die etwa in Textform vorliegen, unumgänglich. Darüber hinaus führen gut aufbereitete Datensätze dazu, dass sich die Trainingszeiten der ML-Lösungen signifikant verkürzen. Die folgenden fünf Tipps helfen dabei, den Prozess der Data Preparation zu optimieren.
1. Aufwand und Zeit in die Vorbereitung investieren
Erfahrungsgemäß beträgt der Anteil der Data Preparation am Gesamtaufwand eines erfolgreichen Data- Science-Projekts rund 80 Prozent. Das liegt nicht zuletzt daran. dass es sich um einen explorativen Ansatz handelt, der das Wiederholen einzelner Arbeitsschritte nicht nur erlaubt, sondern in manchen Fällen sogar erfordert.
Je nach Datensatz können sich die notwendigen Verarbeitungsschritte stark unterscheiden. Was für einen Datensatz hilfreich ist, muss nicht zwingend auch bei anderen Daten sinnvoll sein. Daher gilt es, empirisch verschiedene Verfahren zu erproben, um die Datenbasis bestmöglich für das nachfolgende Modelltraining vorzubereiten. Auch nach dem ersten Modelltraining sollte man diese Maßnahmen kritisch hinterfragen und gegebenenfalls anpassen.
2. Datenvorbereitung in Teilabschnitte gliedern
Es hat sich bewährt, bei der Datenaufbereitung schrittweise vorzugehen, nämlich:
I. Data Exploration
Jede Data Preparation erfordert zunächst eine Explorationsphase, um die Datenqualität beurteilen zu können und ein grundlegendes Verständnis über die Daten zu erhalten. Mithilfe statistischer Verfahren lassen sich
- Extremwerte (Minima, Maxima, Anzahl fehlender Werte),
- Lagemaße (arithmetischer Mittelwert, Median, Modus),
- Streuungsmaße (Standardabweichung, Varianzen) sowie
- Zusammenhangmaße (positive und negative Korrelationen)
erkennen.
II. Feature Cleansing
Im zweiten Schritt findet die Datenbereinigung statt. Fehlende Werte haben die Merkmalsausprägung Null, beziehungsweise sind leer. Die meisten ML-Modelle können solche Größen aber nicht verarbeiten, was ein Modelltraining unmöglich macht. Man muss sie deshalb entweder eliminieren oder durch gültige Werte ersetzen.
Ein weiteres Problem sind Ausreißer und falsche Daten, die sich negativ auf die Performance der Modelle auswirken und unter anderem Overfitting verursachen können. Sie sind daher ebenfalls zu entfernen beziehungsweise zu nivellieren. Es sei denn, das Ziel des Data-Science-Projektes ist die Anomaly Detection. In diesem Fall sollten die Fehlwerte durch valide Werte ersetzt werden, beispielsweise durch den Wert 0 oder durch den Durchschnittswert. Man spricht hierbei auch von Imputing. Die Praxis zeigt, dass Unternehmen oft zu undifferenziert vorgehen und den Fehler machen, Fehlwerte generell zu entfernen.
III. Feature Engineering
Eine wirksame Methode, die Trainingszeit des Modells zu verkürzen und seine Vorhersagequalität zu verbessern, ist das Gruppieren von Daten, auch Binning genannt: Weniger Datensätze erfordern weniger Training, Ausreißer fallen weniger ins Gewicht. Liegen die Features zudem in Formaten vor, die sich maschinell nicht verarbeiten lassen, erfolgt jetzt ihre Überführung in die numerische Form.
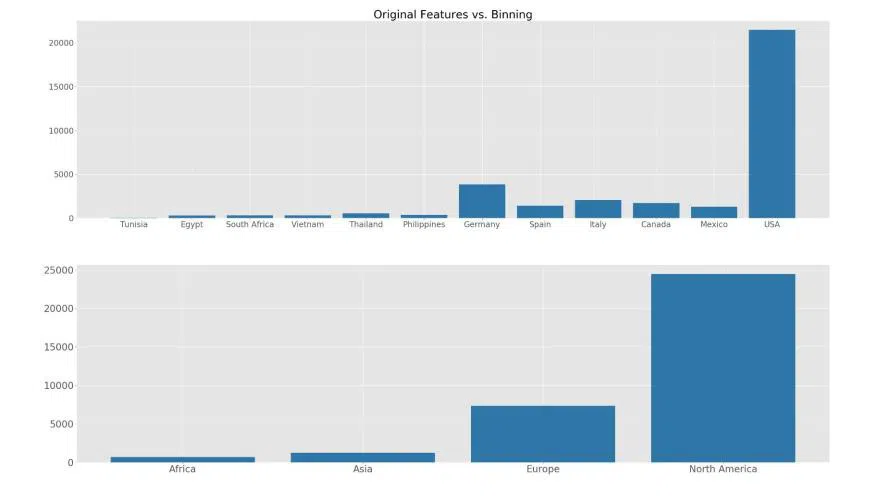
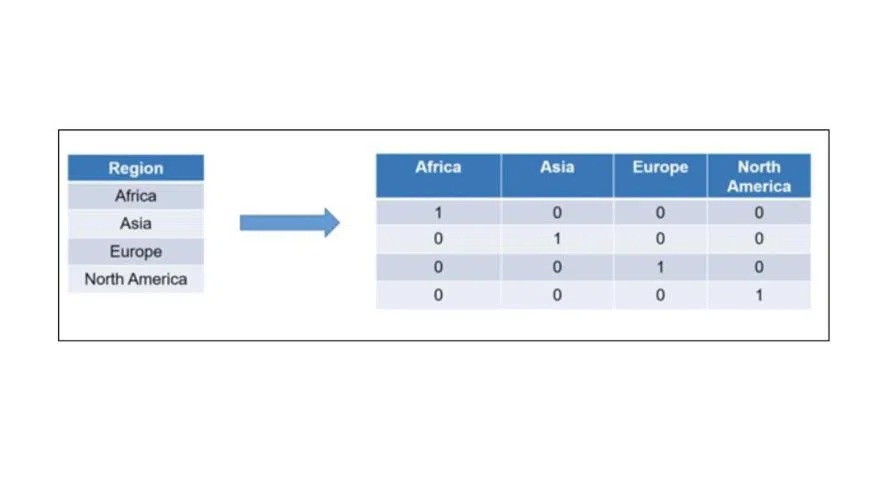
IV. Feature Selection
In der Regel enthalten Datensätze auch Features, die für das vorliegende Data-Science-Projekt irrelevant sind. Sie sollen nicht in die Modellierung einfließen, denn mit der Anzahl der Merkmale verlängern sich die Trainingszyklen, während die Vorhersagegenauigkeit abnimmt. Zudem gibt es Modelle, die überhaupt nur mit einer begrenzten Datenzahl arbeiten können. Filter dienen dazu, Daten sinnvoll auszuwählen, beispielsweise nach ihrer Relevanz zur Zielvariablen oder nach der Anzahl der fehlenden Werte.

3. Visualisierungen nutzen
Bereits in der Explorationsphase, jedoch auch später beim Feature Engineering ist es sinnvoll, geeignete Visualisierungsmethoden zu nutzen. Menschen erfassen bildliche Darstellungen in der Regel leichter und können sich so sehr schnell und unkompliziert einen Überblick über die Datenverteilung verschaffen.
Gängige Diagrammformen helfen dabei, die Distribution und Eigenschaften der Daten auf einen Blick zu erfassen.
- So veranschaulicht ein Punkt- oder Streudiagramm gut, ob zwei Merkmale korrelieren.
- Ein Histogramm gibt Aufschluss über die Häufigkeitsverteilung von Merkmalen, etwa der Standardabweichung und der Varianz.
- Ein Box-Plot (Kastengrafik) eignet sich besonders gut, um Ausreißer zu erkennen und die Datenstreuung aufzuzeigen.
- Ein Plot der Autokorrelation ist ein übliches Mittel im Bereich der Zeitreihenprognose. Hierdurch lässt sich die Abhängigkeit der Zeitreihenvariable mit sich selbst zu einem früheren Zeitpunkt darstellen.
- Eine Korrelationsmatrix visualisiert die Korrelationskoeffizienten zwischen den untersuchten Features. So können bivariate Abhängigkeiten anhand der Farbgebung identifiziert werden. Rote Kacheln zeigen eine positive und blaue Kacheln eine negative Korrelation auf.
4. Datenqualität deutlich erhöhen
Schwachpunkte in den Datensätzen lassen sich auf mehreren Wegen ausmerzen:
- Handelt es sich um Missing Values, die auf Messfehler zurückgehen, kann man sie einfach aus dem Datensatz entfernen.
- Liegen andere Ursachen zugrunde, dann sind sie durch gültige Größen zu ersetzen, etwa durch Dummies sowie Durchschnittswerte oder indem man das Modell mit allen vorhandenen Merkmalsausprägungen trainiert und das Modell selbst die Missing Values ermittelt.
- Bei Zeitreihen kann es sinnvoll sein, anstelle einer fehlenden Angabe den letzten bzw. den ersten der nachfolgenden gültigen Werte einzusetzen.
- Eine Skalierung hingegen, zum Beispiel durch logarithmische Transformation, hilft, den Einfluss von Ausreißern zu reduzieren
5. Data Preparation einbetten
Als Standardprozess für Data Mining hat sich CRISP-DM (Cross Industry Standard Process for Data Mining) etabliert. Auch hier handelt es sich um einen iterativen Prozess, der nicht zwingend linear verläuft und Rücksprünge – selbst gegen den Uhrzeigersinn – zulässt. Wie die Modellierungsphase abläuft, hängt dabei ganz maßgeblich von der Data Preparation ab.
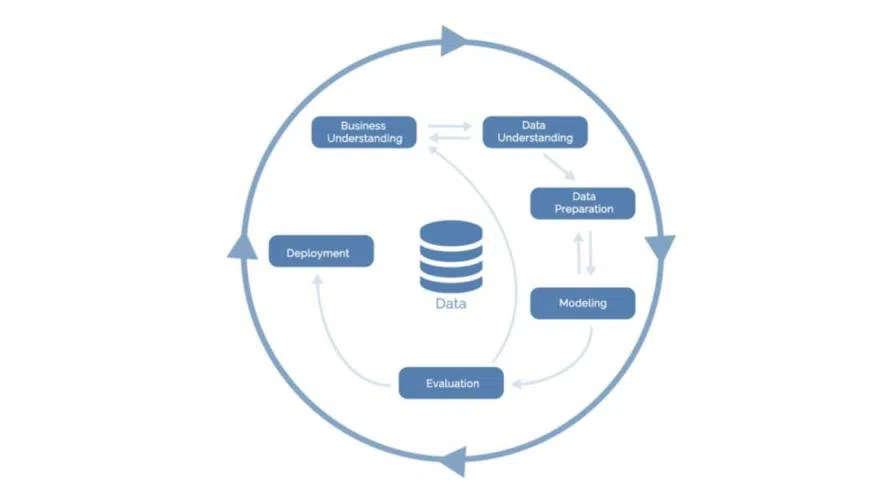
Die Phasen der CRISP-DM-Methode:
- Business Understanding: Es geht darum, Domänenwissen zu erhalten, etwa woher die Daten stammen, was das Ziel des Data-Science Projektes ist und welchen Business Value das Unternehmen der Lösung beimisst.
- Data Understanding: Die Explorationsphase ist absolut unverzichtbar. Sie dient dazu, mittels univariater und bivariater Statistik Schwachstellen in der Datenqualität zu erkennen, wie etwa Ausreißer oder fehlende Werte. Zudem geben Visualisierungen erste Hinweise über Datenverteilungen und Korrelationen.
- Data Preparation: Hier finden proaktive Maßnahmen statt, um die Qualität der Daten signifikant zu verbessern und sie optimal für die spätere Modellierung vorzubereiten. Diese Phase umfasst das Entwickeln neuer Features sowie die Selektion relevanter Merkmale.
- Modelling: Zunächst sind die passenden Modelle auszuwählen. Danach folgt die Trainingsphase und anschließend das Modell Tuning für die Hyperparameter, um die Modelle zu optimieren. Sind die Daten sehr gut aufbereitet, verkürzen sich die erforderlichen Trainingszeiten.
- Evaluation: Es ist unerlässlich, ein Modell hinsichtlich seiner Vorhersagegüte zu überprüfen. Dafür kommen verschiede Metriken bzw. Modellvergleiche zum Einsatz. Die Ergebnisse sind Grundlage für Modell Tuning in puncto Hyperparameter oder führen dazu, dass man die Modellierung mit geänderten Annahmen wiederholt.
- Deployment: Sobald die Vorhersagequalität des Datenmodells die Anforderungen erfüllt, erfolgt seine Produktivnahme. Dazu gehören das Training mit neuen Daten, das Reporting sowie das Bereitstellen von Schnittstellen, um das Modell schließlich in bestehende Softwarelösungen zu integrieren.
*Michael Deuchert ist Data Scientist bei der it-novum GmbH.









Be the first to comment