
PyTorch 1.10 ist ab sofort produktionsreif und bietet ein reichhaltiges Ökosystem an Tools und Bibliotheken für Deep Learning, Computer Vision, natürliche Sprachverarbeitung und mehr. Hier erfahren Sie, wie Sie mit PyTorch loslegen können. [...]

PyTorch (weiterführende Artikel in Englisch) ist ein Open-Source-Framework für maschinelles Lernen, das sowohl für Forschungsprototypen als auch für den Produktionseinsatz verwendet wird. Laut dem Quellcode-Repository bietet PyTorch zwei wichtige Funktionen:
- Tensor-Berechnungen (wie NumPy) mit starker GPU-Beschleunigung.
- Tiefe neuronale Netze, die auf einem bandbasierten Autograd-System aufgebaut sind.
Ursprünglich wurde PyTorch am Idiap Research Institute, der NYU, NEC Laboratories America, Facebook und Deepmind Technologies mit Unterstützung der Torch- und Caffe2-Projekte entwickelt und hat inzwischen eine florierende Open Source Community. PyTorch 1.10, veröffentlicht im Oktober 2021, hat Commits von 426 Mitwirkenden, und das Repository hat derzeit 54.000 Sterne.
Dieser Artikel gibt einen Überblick über PyTorch, einschließlich neuer Funktionen in PyTorch 1.10 und einer kurzen Anleitung für den Einstieg in PyTorch.
Die Evolution von PyTorch
Schon früh fühlten sich Akademiker und Forscher zu PyTorch hingezogen, weil es für die Modellentwicklung mit Grafikprozessoren (GPUs) einfacher zu verwenden war als TensorFlow. PyTorch ist standardmäßig auf den Eager Execution Mode eingestellt, was bedeutet, dass seine API-Aufrufe ausgeführt werden, wenn sie aufgerufen werden, anstatt einem Graphen hinzugefügt zu werden, um später ausgeführt zu werden.
TensorFlow hat inzwischen seine Unterstützung für den Eager-Execution-Modus verbessert, aber PyTorch ist in der akademischen und Forschungsgemeinschaft immer noch sehr populär.
PyTorch ist mittlerweile produktionsreif und erlaubt es, mit TorchScript einfach zwischen Eager- und Graphmodus zu wechseln und mit TorchServe den Weg zur Produktion zu beschleunigen. Das torch.distributed Backend ermöglicht skalierbares verteiltes Training und Leistungsoptimierung in Forschung und Produktion, und ein reichhaltiges Ökosystem von Tools und Bibliotheken erweitert PyTorch und unterstützt die Entwicklung in den Bereichen Computer Vision, Natural Language Processing und mehr.
Des Weiteren wird PyTorch von den wichtigsten Cloud-Plattformen unterstützt, darunter Alibaba, Amazon Web Services (AWS), Google Cloud Platform (GCP) und Microsoft Azure. Die Cloud-Unterstützung ermöglicht eine reibungslose Entwicklung und einfache Skalierung.
Was ist neu in PyTorch 1.10
Laut dem PyTorch-Blog konzentrierten sich die Aktualisierungen von PyTorch 1.10 auf die Verbesserung von Training und Leistung sowie auf die Benutzerfreundlichkeit für Entwickler. Details finden Sie in den PyTorch 1.10 Release Notes. Hier sind nur ein paar Highlights dieser Version:
- CUDA Graphs APIs wurden integriert, um den CPU-Overhead für CUDA-Workloads zu reduzieren.
- Mehrere Front-End-APIs wie FX, torch.special und nn.Module-Parametrisierung wurden von Beta auf Stable umgestellt. FX ist eine Pythonic-Plattform zur Umwandlung von PyTorch-Programmen; torch.special implementiert spezielle Funktionen wie Gamma- und Bessel-Funktionen.
- Ein neuer LLVM-basierter JIT-Compiler unterstützt die automatische Fusion sowohl auf CPUs als auch auf GPUs. Der LLVM-basierte JIT-Compiler kann Sequenzen von torch-Bibliotheksaufrufen verschmelzen, um die Leistung zu verbessern.
- Android NNAPI-Unterstützung ist jetzt als Beta-Version verfügbar. NNAPI (Android’s Neural Networks API) ermöglicht es Android-Anwendungen, rechenintensive neuronale Netze auf den leistungsstärksten und effizientesten Teilen der Chips auszuführen, die Mobiltelefone antreiben, einschließlich GPUs und spezialisierter neuronaler Verarbeitungseinheiten (NPUs).
Die Version PyTorch 1.10 enthielt über 3.400 Commits, was auf ein sehr aktives Projekt schliessen lässt, das sich auf die Verbesserung der Leistung durch eine Vielzahl von Methoden konzentriert.
Erste Schritte mit PyTorch
Die Lektüre der Versions-Updates wird Ihnen nicht viel bringen, wenn Sie die Grundlagen des Projekts nicht verstehen oder nicht wissen, wie Sie es benutzen können.
Die PyTorch-Tutorial-Seite bietet zwei Wege: Einen für diejenigen, die mit anderen Deep-Learning-Frameworks vertraut sind, und einen für Neulinge. Wenn Sie den Einsteigertrack benötigen, der in Tensoren, Datensätze, Autograd und andere wichtige Konzepte einführt, schlage ich vor, dass Sie ihm folgen und die Option Run in Microsoft Learn verwenden, wie in Abbildung 1 gezeigt.
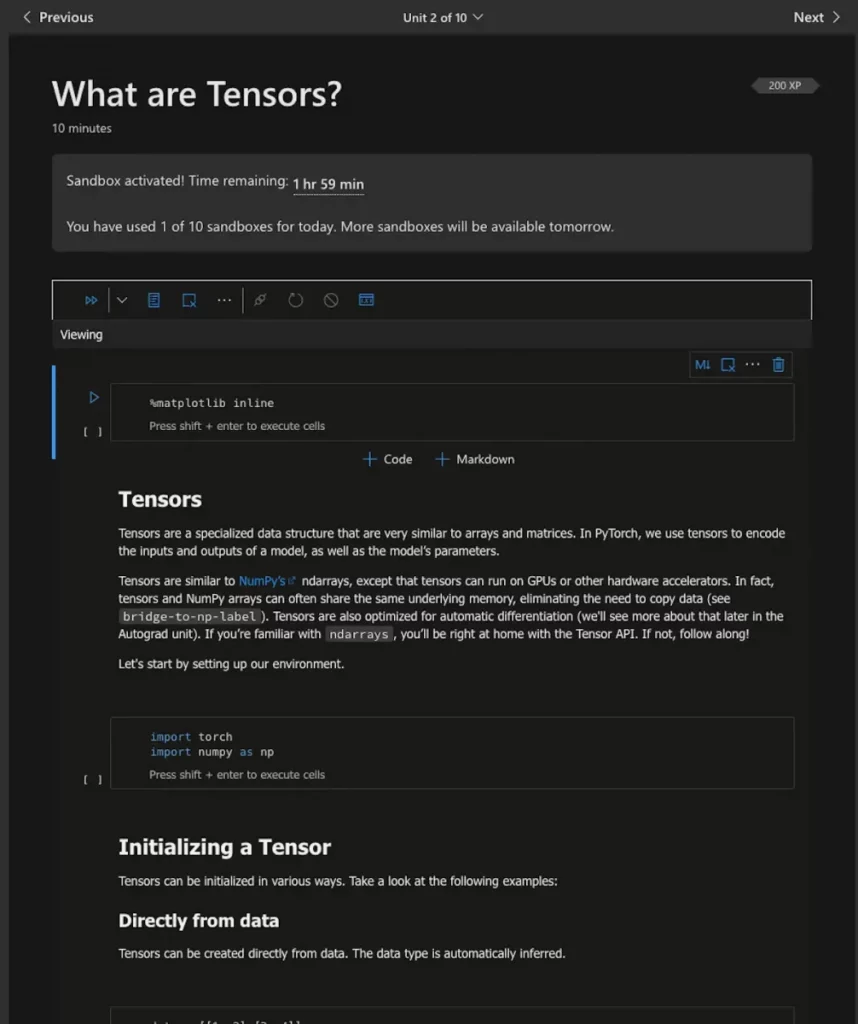
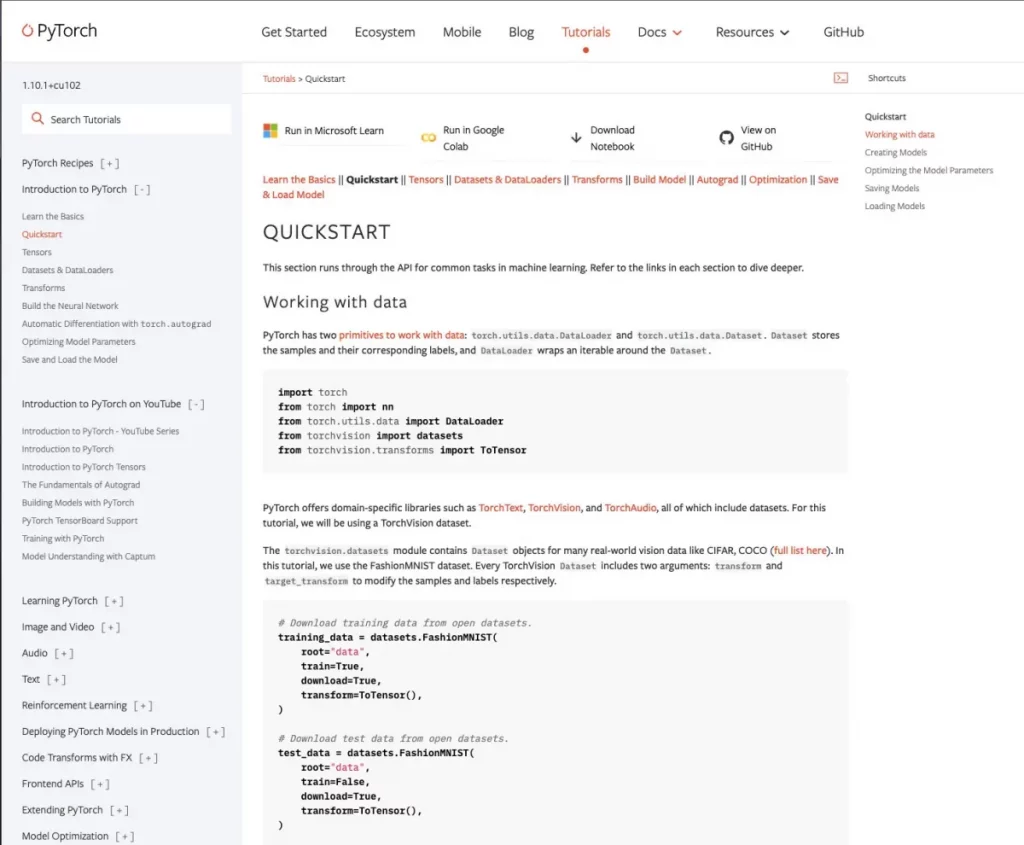
Wenn Sie bereits mit Deep Learning-Konzepten vertraut sind, empfehle ich Ihnen, das in Abbildung 2 gezeigte Quickstart-Notebook auszuführen. Sie können auch auf „Run in Microsoft Learn“ oder „Run in Google Colab“ klicken oder das Notebook lokal nutzen.
Interessante PyTorch-Projekte
Wie auf der linken Seite des Screenshots in Abbildung 2 zu sehen ist, verfügt PyTorch über zahlreiche Rezepte und Tutorials. Außerdem gibt es zahlreiche Modelle und Beispiele für deren Verwendung, in der Regel in Form von Notebooks. Drei Projekte aus dem PyTorch-Ökosystem erscheinen mir besonders interessant: Captum, PyTorch Geometric (PyG) und skorch.
Captum
Wie auf dem GitHub-Repository dieses Projekts vermerkt, bedeutet das Wort Captum im Lateinischen „Verstehen“. Wie auf der Repository-Seite und anderswo beschrieben, ist Captum „eine Modellinterpretationsbibliothek für PyTorch“. Sie enthält eine Vielzahl von gradienten- und störungsbasierten Attributionsalgorithmen, die zur Interpretation und zum Verständnis von PyTorch-Modellen verwendet werden können. Sie bietet auch eine schnelle Integration für Modelle, die mit domänenspezifischen Bibliotheken wie torchvision, torchtext und anderen erstellt wurden.
Abbildung 3 zeigt alle Attributionsalgorithmen, die derzeit von Captum unterstützt werden.

PyTorch Geometric (PyG)
PyTorch Geometric (PyG) ist eine Bibliothek, die Datenwissenschaftler und andere nutzen können, um neuronale Graphen-Netzwerke für Anwendungen im Zusammenhang mit strukturierten Daten zu schreiben und zu trainieren. Wie auf seiner GitHub-Repository-Seite erläutert:
PyG bietet Methoden für Deep Learning auf Graphen und anderen unregelmäßigen Strukturen, auch bekannt als geometrisches Deep Learning. Darüber hinaus besteht es aus einfach zu bedienenden Mini-Batch-Ladern für die Bearbeitung vieler kleiner und einzelner riesiger Graphen, Multi-GPU-Unterstützung, verteiltem Graphenlernen über Quiver, einer großen Anzahl gängiger Benchmark-Datensätze (basierend auf einfachen Schnittstellen zur Erstellung eigener Daten), dem GraphGym-Experiment-Manager und hilfreichen Transformationen, sowohl für das Lernen auf beliebigen Graphen als auch auf 3D-Netzen oder Point Clouds.
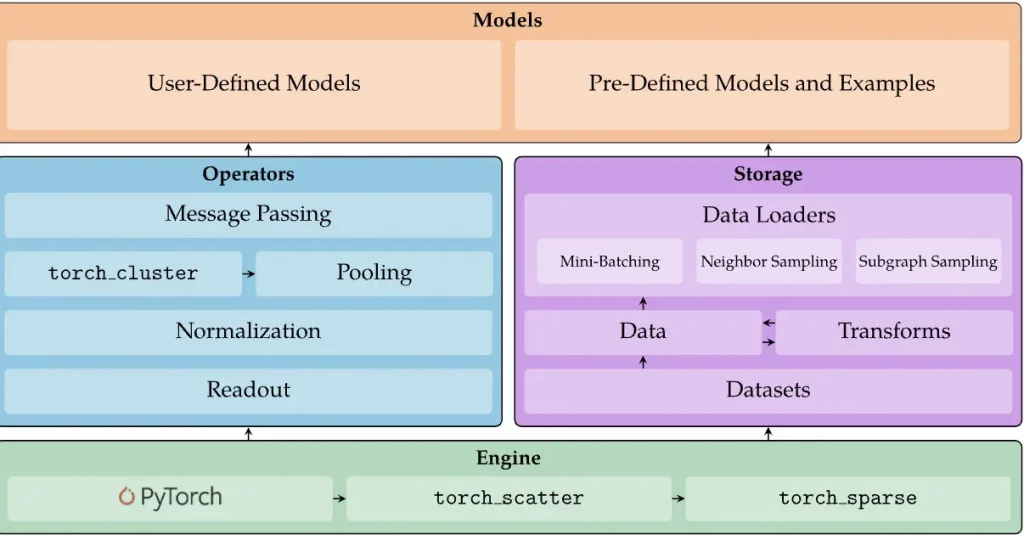
Abbildung 4 gibt einen Überblick über die Architektur von PyTorch Geometric.
skorch
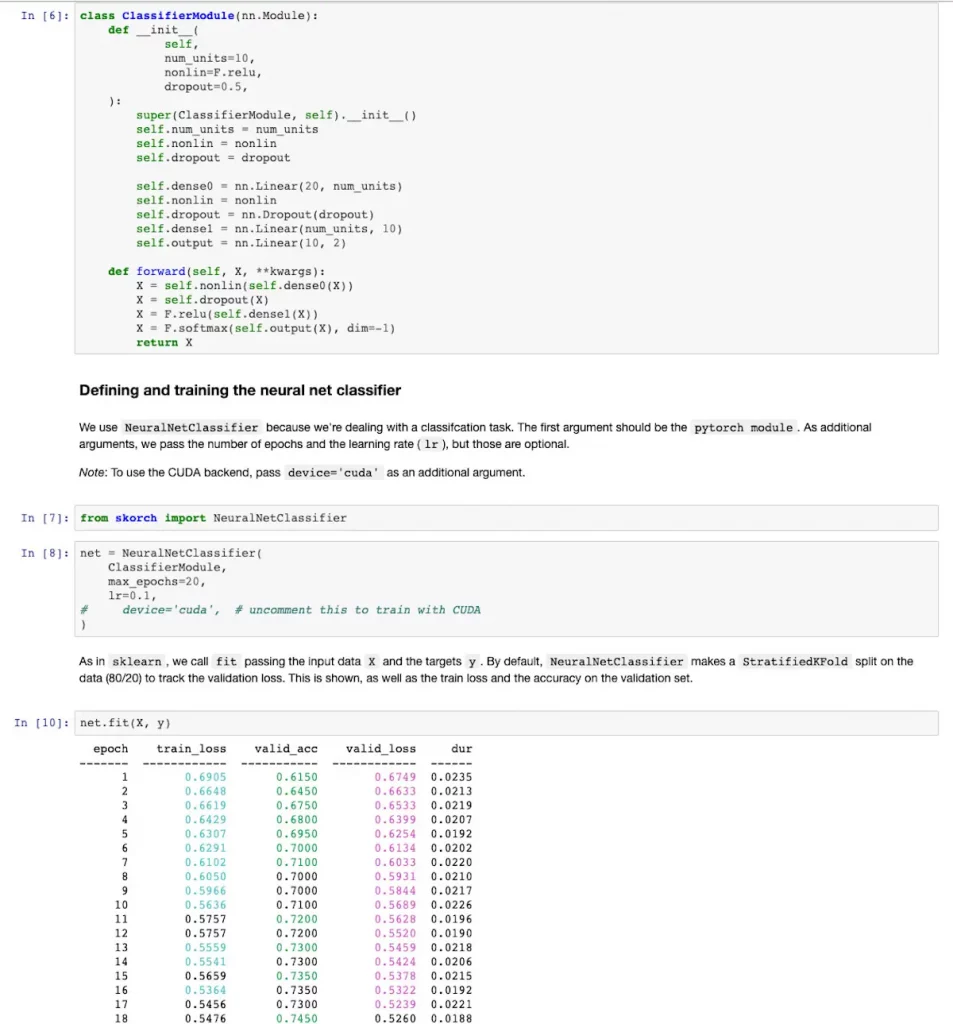
skorch ist eine Scikit-Learn-kompatible Bibliothek für neuronale Netze, die PyTorch umhüllt. Das Ziel von skorch ist es, die Verwendung von PyTorch mit sklearn zu ermöglichen. Wenn Sie mit sklearn und PyTorch vertraut sind, müssen Sie keine neuen Konzepte lernen, und die Syntax sollte Ihnen gut bekannt sein. Darüber hinaus abstrahiert Skorch die Trainingsschleife, wodurch eine Menge Standardcode überflüssig wird. Ein einfaches net.fit(X, y) reicht aus, wie in Abbildung 5 dargestellt.
Fazit
Insgesamt ist PyTorch eines der wenigen erstklassigen Frameworks für tiefe neuronale Netze mit GPU-Unterstützung. Sie können es für die Modellentwicklung und die Produktion verwenden, Sie können es vor Ort oder in der Cloud ausführen, und Sie können viele vorgefertigte PyTorch-Modelle finden, die Sie als Ausgangspunkt für Ihre eigenen Modelle verwenden können.
*Martin Heller ist mitwirkender Redakteur und Rezensent bei InfoWorld. Als ehemaliger Berater für Web- und Windows-Programmierung entwickelte er von 1986 bis 2010 Datenbanken, Software und Websites. In jüngster Zeit war er als Vizepräsident für Technologie und Bildung bei Alpha Software sowie als Vorsitzender und CEO bei Tubifi tätig.









Be the first to comment