
Maschinelles Lernen (ML) gilt als Schlüsseltechnologie zur Neu- und Weiterentwicklung von Produkten, Prozessen und Dienstleistungen. Auch wenn die Aufgabenstellungen sehr unterschiedlich sind, ist die Vorgehensweise oft die gleiche. [...]

Die Anwendungsbereiche von maschinellem Lernen sind sehr weit gestreut und haben teilweise bereits Einzug in unseren Alltag gefunden. Klassifikationsverfahren werden dazu verwendet automatisch Spam E-Mails zu filtern, Kundenabwanderung vorherzusagen, Kunden zu segmentieren und Betrugserkennungen vorzunehmen.
Des Weiteren werden Regressionsverfahren für Preisvorhersagen genutzt und kommen im Risikomanagement zum Einsatz. Auch die weit verbreiteten Kaufempfehlungen und individuellen Vorschläge, beispielsweise bei Musik- und Filmtiteln, verwenden Verfahren aus dem maschinellen Lernen. Obwohl diese Anwendungsbereiche sehr diversifiziert sind, gibt es wesentliche und gemeinsame Schritte beim Aufbau entsprechender Modelle.
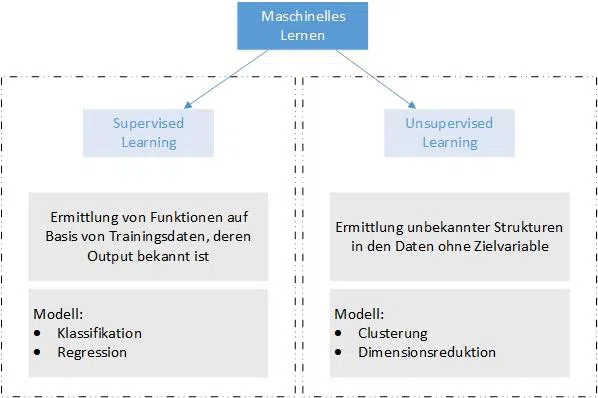
Supervised und unsupervised Learning
Das maschinelle Lernen unterscheidet grundsätzlich zwei Lernansätze. Zum einen können Verfahren des überwachten Lernens, nachfolgend als supervised Learning bezeichnet, zur Anwendung kommen. Dabei werden die Daten vor der Verarbeitung markiert. Zum anderen gibt es unüberwachtes Lernen, nachfolgend als unsupervised Learning bezeichnet.
Supervised Learning
Beim supervised Learning geht es darum eine Funktion zu finden, mit der ungesehene bzw. unbekannte Beobachtungen eines Datensets einer Klasse oder einem Wert zugewiesen werden können. Hierfür werden die Daten mit einem sogenannten Label versehen. Die Anwendungsfälle für supervised Learning sind Regressionen, Klassifikationen, Empfehlungen und Imputationen.
Unsupervised Learning
Ziel des unsupervised Learning Ansatz ist es, aus den Daten unbekannte Muster zu erkennen und Regeln aus diesen abzuleiten. Hier kommen Verfahren wie das Gaussian Mixture Model und der k-Means Algorithmus zum Einsatz.
Für die Anwendung von unsupervised Learning Algorithmen werden in der Regel sehr viele Daten benötigt. Ohne ausreichende Datenmenge sind die Algorithmen nicht in der Lage Clusterungen vorzunehmen und damit eine entsprechende Prognose über einen unbekannten Datensatz bzw. ein ungesehenes Datenset zu erstellen.
Vor- und Nachteile beider Verfahren
Die Verfahren im supervised Learning sind aufgrund ihrer Strukturiertheit gut nachvollziehbar. Es besteht die Möglichkeit verschiedene Verfahren gegenüberzustellen, zu parametrisieren und dadurch eine für den Anwendungsfall optimale Lösung zu finden. Die Interpretation der Daten ist durch die gegebene Nachvollziehbarkeit einfacher als bei unsupervised Learning Methoden.
Der Nachteil besteht jedoch in einem oft sehr hohem manuellen Aufwand bei der Aufbereitung der Daten.
Die Vorteile des unsupervised Learning bestehen in der teilweise vollautomatisierten Erstellung von Modellen. Dabei können diese eine sehr gute Prognose über neue Daten hervorbringen oder gar neue Inhalte erstellen. Das Modell lernt mit jedem neuen Datensatz dazu und verfeinert gleichzeitig seine Berechnungen und Klassifizierungen. Ein manueller Eingriff ist dadurch nicht mehr notwendig. Neuronale Netze sowie das klassische Verständnis über künstliche Intelligenz basieren auf diesen selbstlernenden Verfahren.
Durch das Trainieren der Modelle werden diese immer mehr an die Eingangsdaten angepasst. Dies führt ab einem bestimmten Zeitpunkt zu einem sogenannten Overfitting, bei dem das Modell zwar gute Prognosen in Bezug auf eine bekannte Datenkategorie besitzt. Neuartige, unbekannte Daten werden jedoch nicht mehr richtig zugeordnet. Zudem kann es auch zu einem sogenannten Underfitting kommen, bei dem zu wenige Daten zum Modellaufbau bereitgestellt wurden und somit die Klassifizierung zu ungenau ist. Auch das führt zu schlechten Prognoseergebnissen.
Ab wann ein Modell ausreichend trainiert ist, also weder Overfitted noch Underfitted ist, kann nur durch Ausprobieren und Testen herausgefunden werden. Dabei handelt es sich um einen sehr aufwendigen Prozess.
Vorgehen beim Aufbau von maschinellen Lernmodellen
Das Sammeln und die Aufbereitung der Daten sind die ersten Schritte zum Aufbau eines Modells. In der Regel sind die verwendeten Daten unvollständig und in keinem einheitlichen Format. Um die Daten verarbeiten zu können, sind diese meist in tabellarische Form zu bringen. Fehlende Werte können beispielsweise mit Hilfe von Imputation ergänzt werden.
Die aufbereiteten Daten werden anschließend analysiert, um herauszufinden wie die Daten aufgebaut sind und welche Abhängigkeiten es gibt. Sind die für die Prognosen wichtigen Variablen identifiziert, können verschiedene statistische Modelle verwendet werden. Nicht jedes Modell eignet sich gleichermaßen gut. Wie geeignet das jeweilige Modell ist, muss über eine Evaluation herausgefunden werden. Dieser Prozess ist in der Regel sehr aufwendig. Um ein gutes Prognosemodell zu finden, sollten verschiedene Verfahren getestet und gegenübergestellt werden. Ist ein passendes Modell gefunden, kann dieses meist noch optimiert werden. Anschließend kann das Modell zur Erstellung von Prognose auf neue Daten angewandt werden.
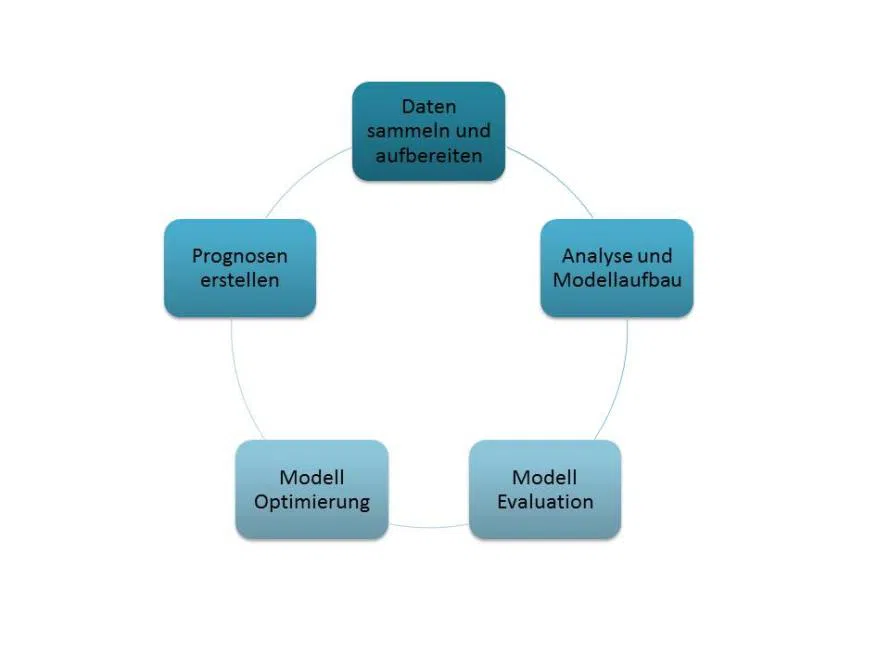
Der Prozess ist als Kreislauf zu verstehen, da es, wie bei klassischen Data Warehouse und Business Intelligence Anforderungen, während der Entwicklung neue Erkenntnisse geben kann, die Änderungen in den Ausgangsdaten oder dem Modell nach sich ziehen.
Die Chancen zur Verbesserung bestehender Prozesse und Produkte sowie die Entwicklung neuer und hochwertigerer Service- und Dienstleistungen sind dank maschinellem Lernen enorm. Eine Auseinandersetzung mit der Thematik kann sich für viele Unternehmen lohnen, trotz der moderaten Anfangsinvestitionen. Wichtig sind eine klare Zielsetzung und Abgrenzung der Anwendungsfälle, da bereits kleine Änderungen in der Ausgangssituation große Auswirkungen auf die Zuverlässigkeit des Modells haben können. Eine gewisse Frustrationstoleranz ist ebenfalls wichtig, da die Modelle bis zur Fertigstellung meist mehrere Iterationen durchlaufen.
*Mandy Goram leitet den Bereich Business Intelligence eines mittelständischen pharmazeutischen Unternehmens. Ihr Schwerpunkt liegt in der strategischen und operativen Weiterentwicklung der unternehmensweiten DWH-, BI- und Analytics-Systeme.









Be the first to comment