
Intelligentes Datenmanagement ist die Basis für nutzbringende Analysen. Dabei unterstützen Künstliche Intelligenz und Maschinelles Lernen. [...]

Eines steht fest: An Daten, die sie erfassen, aufbereiten und analysieren können, mangelt es Unternehmen und Organisationen nicht. In der Studie „Global Datasphere 2020“ taxiert das Marktforschungsunternehmen IDC den weltweiten Datenbestand auf derzeit 59 Zettabyte. Bis zum Jahr 2024 wird er ein Volumen von etwa 140 Zettabyte erreichen. Davon entfallen etwa 29 Prozent auf Daten in den Sparten Produktivität und „Embedded“. Dies sind Informationen, die beispielsweise Geschäftsanwendungen erzeugen, aber auch Daten von Sensoren und „Dingen“ wie vernetzten Maschinen, Fahrzeugen und Verkehrsleitsystemen.
Diese Informationsbestände bilden die Grundlage für den Aufbau digitaler Geschäftsmodelle. Das untermauert Christian Leutner, Head of Product Sales Europe bei Fujitsu TDS: „Unternehmen müssen heute Daten aller Art in Echtzeit erfassen, auswerten und in verwertbare ‚Insights‘ umsetzen. Nur dann sind sie in der Lage, einen geschäftlichen Nutzen aus ihren Datenbeständen zu ziehen.“ Das erfordert Leutner zufolge eine datenorientierte (‚data-driven‘) Transformationsstrategie. „Eines der Schlüsselelemente einer solchen Strategie ist der Einsatz von Künstlicher Intelligenz und maschinellem Lernen in Verbindung mit Data Science.
“Doch damit Data Scientists und die von ihnen eingesetzten KI- und Machine-Learning-Algorithmen zu „richtigen“ Analyseergebnissen kommen, benötigen sie eine solide Datenbasis. Denn sonst tritt bei Data-Analytics-Projekten ein Effekt auf, der IT-Fachleuten schon seit vielen Jahren bekannt ist: „Garbage in – Garbage out“. Das heißt, wenn fehlerhafte oder unpassende Informationen für eine Analyse herangezogen werden, dann ist das Ergebnis schlicht und einfach Datenmüll statt Insights.
Doch Garbage zu vermeiden, ist keine triviale Aufgabe, so Daniel Fallmann, Gründer und CEO des österreichischen Unternehmens Mindbreeze. Es hat sich auf Lösungen spezialisiert, die Daten und Dokumente aus unterschiedlichen Quellen erfassen, in einen Kontext einbinden und Nutzern zur Verfügung stellen. „Die größte Hürde für eine klare Sicht auf die Daten sind die unterschiedlichen Datenquellen in einem Unternehmen. Eine weitere Herausforderung besteht darin, zu ermitteln, was das Unternehmen bereits weiß“, sagt Fallmann. Ein zusätzliches Problem ist aus seiner Sicht, dass Datenquellen parallel ohne direkte Verbindung zueinander existieren – quasi als Datensilos. „Die Daten nur zu besitzen, bringt noch keinen Mehrwert. Erst wenn diese entsprechend aufbereitet wurden und dann im richtigen Moment und Kontext zur Verfügung stehen, können Unternehmen diese als Entscheidungsgrundlage heranziehen oder Arbeitsprozesse effizienter gestalten“, so Fallmann weiter. Dafür müssten Datensilos aufgebrochen werden, um die Daten anschließend mit Methoden der Künstlichen Intelligenz aufzubereiten.
So geht’s:
Mit Augmented Data Management startenUnternehmen, die mit Augmented Data Management starten möchten, sollten sich im Vorfeld mit den folgenden Punkten befassen:
Use Cases definieren: Anwender sollten prüfen, welche Einsatzmöglichkeiten von ADM für ihr Unternehmen in Betracht kommen. Ein Finanzdienstleister kann beispielsweise automatisch neue Portfolios mit Aktien und Anlageoptionen für bestimmte Kundengruppen erstellen. Die Grundlage bilden Metadaten, die eine Plattform für das Management und die Analyse vorhandener Kunden- und Marktdaten bereitstellt.
Eine Bankengruppe wiederum setzt ADM ein, um den Füllstand von Geldautomaten zu optimieren. KI- und Machine-Learning-Algorithmen schätzen ab, wann die Bargeldmenge in Automaten einen kritischen Punkt erreicht und ein Nachfüllen erforderlich ist. Dazu müssen jedoch Daten aus unterschiedlichen Quellen in diversen Formaten automatisch erfasst, aufbereitet und analysiert werden.
Mitarbeiter mitnehmen: Mitarbeiter stehen häufig Lösun-gen mit KI- und Machine-Learning-Funktionen skeptisch gegenüber. Der Grund: Furcht um den Arbeitsplatz. Das ist möglicherweise auch bei den hauseigenen Datenspezialisten der Fall. Daher im Vorfeld klarmachen, dass Augmented Data Management kein Jobkiller ist, sondern den Data Scientists ungeliebte Routinearbeiten abnimmt.
Data Governance berücksichtigen: Beim Zugriff auf Daten über ein ADM-System müssen die geltenden Datenschutzregelungen berücksichtigt werden. Daher sollte der Zugang zu Informationen mithilfe von Regelwerken (Policies) gesteuert werden, die in der ADM-Software hinterlegt sind. Das verringert das Risiko, dass Datenlecks und Verstöße gegen die Datenschutz-Grundverordnung auftreten.
IT-Ressourcen anpassen: KI und Machine Learning sind Technologien, die hohe Anforderungen an Server, Storage und Netzwerkverbindungen stellen. Die IT-Ausstattung muss dementsprechend angepasst werden. Eine Option ist, für das erweiterte Datenmanagement eine Cloud-Plattform zu nutzen. Ein Großteil der Anbieter von ADM-Lösungen verfügt mittlerweile über eine Cloud-Version oder setzt auf einen cloudnativen Ansatz. Zu beachten sind dabei jedoch ebenfalls die Punkte Data Governance und Datenschutz.
Wahlfreiheit bei Implementierung und Nutzung: Im Idealfall steht eine ADM-Lösung allerdings nicht nur als Cloud-Plattform zur Verfügung. Vielmehr sollte der Anwender zwischen mehreren Nutzungsmodellen wählen können: einer Public Cloud, der Implementierung im eigenen Data-Center und einer Hybrid-Cloud.
Data Management und MLOps verknüpfen: Unternehmen sollten prüfen, ob sie ein Augmented Data Management mit einem MLOps-Ansatz (Machine Learning Operations) verknüpfen. Er bindet bei Datenprojekten neben Data Scientists und Datenspezialisten auch KI- und ML-Entwickler, die IT-Abteilung und die Fachabteilungen mit ein.
Augmented Data Management
Für die Verwaltung und das Aufbereiten von Daten etabliert sich derzeit ein neuer Begriff: Augmented Data Management, kurz ADM. Diese Technik greift auf KI und Machine Learning zurück, um die Verwaltung von Daten effektiver und effizienter zu gestalten. „ADM stellt allen Mitarbeitern, die in ein Datenprojekt involviert sind, Werkzeuge zur Verfügung, um Daten zu integrieren, zu konsolidieren, zu transformieren, zu verwalten und zu konsumieren“, erläutert Sofiane Fessi, SE Director für Zentraleuropa bei Dataiku. Ein Augmented Data Management tangiert somit nicht nur die Datenwissenschaftler, sondern auch die Geschäftsbereiche, die IT-Abteilung und die Analysten.
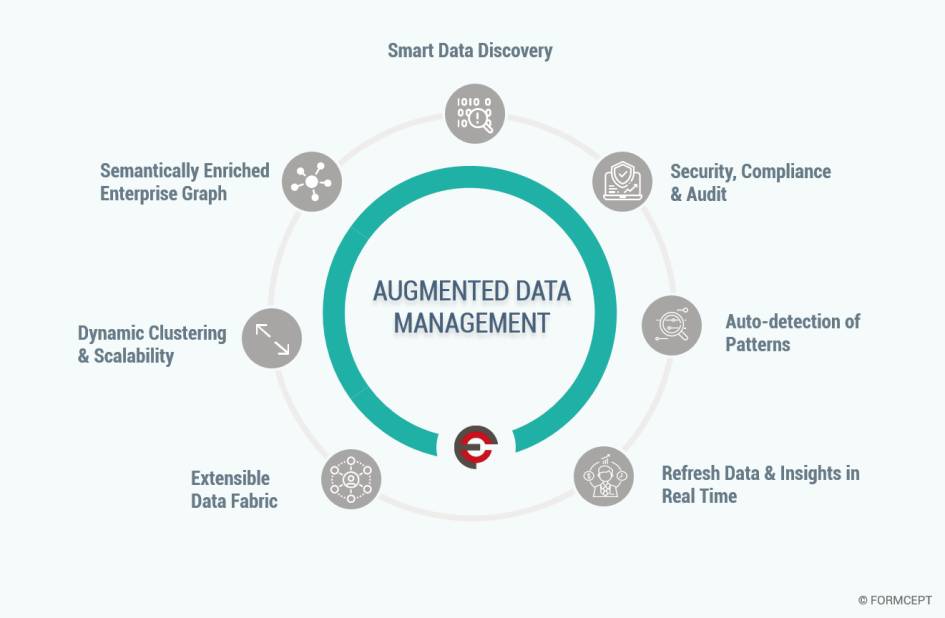
Dass es sich beim erweiterten Datenmanagement um einen ganzheitlichen Ansatz handelt, bestätigt Wolfgang Kobek, Senior Vice President EMEA bei Qlik: „Dem Begriff des ADM entspricht am ehesten der ‚Raw to Ready‘-Ansatz. Darunter verstehen wir die Datenbereitstellung, von den Rohdaten bis hin zu den analysebereiten Informationen.“ Dieser Teil der Datenwertschöpfungskette stehe zwar nicht so im Rampenlicht wie Analytics-Funktionen, sei aber unverzichtbar. Denn ADM trägt Kobek zufolge maßgeblich dazu bei, dass aus Rohdatenquellen verwertbare Informationsquellen für Datenanalysen werden.Wie wichtig ein effektives Datenmanagement für Data Analytics ist, belegt die Studie „The Future of Analytics“ des Marktforschungs- und Beratungsunternehmens BARC. Demnach raten 64 Prozent der Unternehmen, die bereits fortgeschrittene Analysemethoden (Advanced Analytics) einsetzen, im Vorfeld das Data Management auszubauen.
KI und ML
Ein zentrales Element eines „Augmented“ Datenmanagements ist der Einsatz von Künstlicher Intelligenz und maschinellem Lernen. Bislang kamen KI- und ML-Technologien vor allem bei der Analyse von Informationsbeständen zum Einsatz: „KI und ML sind heute bereits bei Arbeiten unverzichtbar, bei denen riesige Datenmengen analysiert werden sollen. Gleiches gilt für Routinearbeiten“, sagt Daniel Fallmann. „Lösungen wie die von Mindbreeze nutzen diese Technologien und helfen dabei, Daten zu verknüpfen und komplexe Zusammenhänge zu verstehen – und diese für den Anwender verständlich darzustellen.
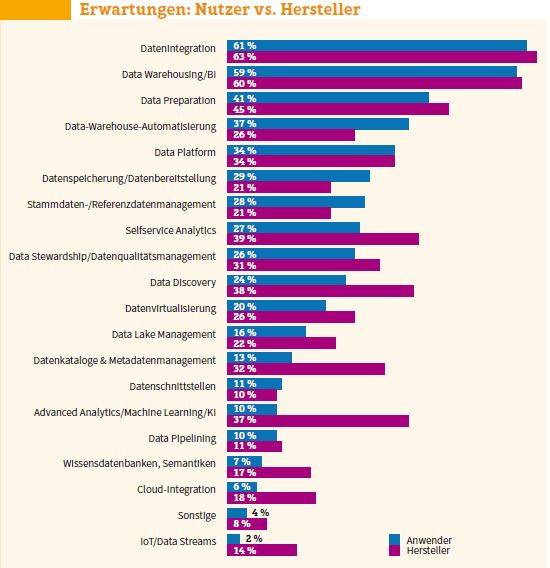
“Bei ADM dienen KI und ML dazu, um den Aufwand zu reduzieren, den die Vorbereitung von Daten für eine Analyse erfordert. Nach Schätzungen des Marktforschungsunternehmens Gartner müssen Datenspezialisten bis zu 60 Prozent ihrer Zeit dafür aufwenden, um das Datenrohmaterial aufzubereiten. Erst nach dieser „Data Preparation“ eignet es sich für die Auswertung mit Hilfe von Analyse-Tools. Gartner rechnet damit, dass sich bis 2024 dank KI und Machine Learning der Anteil der manuellen Tätigkeiten im Bereich Datenmanagement um 45 Prozent reduzieren lässt. Das bedeutet, dass Data Scientists mehr Zeit für die eigentliche Datenanalyse haben. Ein weiterer Vorteil, der oft weniger gern angesprochen wird: Es sind auch weniger Datenspezialisten erforderlich, um dasselbe Arbeitspensum zu bewältigen. Da solche Fachleute derzeit gesucht und damit kostspielig sind, ist dies ein Faktor, der für CIOs und Chief Digital Officers (CDOs) ebenfalls eine wichtige Rolle spielen dürfte.
Zentrale Elemente von ADM
Über welche Eigenschaften eine Plattform oder Software für das Augmented Data Management neben KI und Machine Learning verfügen muss, ist umstritten. Zwar hat das Beratungshaus Gartner eine Definition des Begriffs herausgebracht, doch stößt diese nicht auf ungeteilte Zustimmung. Der Grund liegt auf der Hand: Jeder Anbieter will seine eigenen Lösungen als „ADM-tauglich“ klassifizieren. Gartner zufolge zeichnet sich ein ADM nicht nur durch den Einsatz von KI und Machine Learning aus. Hinzu kommen Automatisierungsfunktionen für die Suche nach relevanten Daten sowie deren Aufbereitung und Bereitstellung. Ein Ziel ist, dass auch „normale“ User, die nicht zur Gilde der Datenspezialisten zählen, Informationsbestände nutzen und in Analysen umsetzen können.
Anbieter von ADM-Plattformen wie das indische Unternehmen MecBot betrachten ADM als „dynamischen und agilen Prozess“, der unter anderem durch folgende Eigenschaften geprägt ist:
- die Verarbeitung großer Datenmengen aus internen und externen Quellen
- eine Bereinigung und Vorverarbeitung dieser Daten
- die Integration von externen „Wissensquellen“, die von der IT-Abteilung oder via Cloud bereitgestellt werden
- das Extrahieren von katalogisierten Datensätzen aus den Rohdaten unter Berücksichtigung von Kontextinformationen, einer Datenverlaufskontrolle (Data Lineage) und von Compliance-Anforderungen
- den Zugang zu verwertbaren Informationen (Insights) durch die automatische Identifizierung (Discovery) von Daten und Datenmustern (Patterns)
- die Konsolidierung von Datenquellen in einer „Data Fabric“.
Zu den Vorzügen einer solchen Datenmanagement-Architektur zählt, dass KI- und ML-Algorithmen in Echtzeit neue Datensätze und deren Beziehung zu bereits vorhandenen Informationen erkennen. Das wirkt sich positiv auf die Qualität und Aktualität von Datenanalysen aus. Außerdem erkennen Algorithmen anhand der Suchanfragen eines Nutzers, welche Informationen er benötigt, und können ihm entsprechende Vorschläge unterbreiten. Das kommt Nutzern zugute, die über keine tief greifenden Kenntnisse im Bereich Data Analytics verfügen. Diese können mittels „Selbstbedienungsfunktionen“ (Selfservice) selbst Datenanalysen vornehmen. Ein Augmented Data Management ermittelt, welche Informationsbestände dafür erforderlich sind, und stellt diese bereit.
ADM-Lösungen lassen sich darüber hinaus dafür verwenden, um mit Machine Learning Anomalien in Datenbeständen zu erkennen. Dazu zählen etwa eine ungewöhnliche Veränderung des Datenvolumens oder atypische Datencharakteristika. Dies kann auf technische Probleme zurückzuführen sein, aber auch auf einen Missbrauch von Daten hinweisen.
Beim Storage ansetzen
Doch damit sich Augmented Data Management mit Erfolg umsetzen lässt, muss auch die darunterliegende Ebene „funktionieren“ – also die der Storage- und Backup-Systeme. Daher setzen auch die Hersteller solcher Lösungen mittlerweile KI und Machine Learning ein. Damit optimieren sie das Management von Daten und stellen sicher, dass Analytics-Anwendungen die benötigten Informationen erhalten.
Ein Beispiel ist Veritas: „Unser Konzept ist, die Daten vom Ursprungs- bis zum Ablageort zu verfolgen, sei es am Edge, im Core oder in der Cloud“, sagt Sascha Oehl, Director Technical Sales DACH bei dem Unternehmen. Der Anbieter hat eine Enterprise Data Management Platform entwickelt. Sie umfasst ein Dateisystem, das auf hoch verfügbaren Clustern basiert, eine Backup-Software, die mehr als 800 Datenquellen unterstützt, sowie die Lösung Enterprise Vault für die Datenarchivierung. KI und maschinelles Lernen kommen bei einer Klassifizierungs-Engine zum Einsatz. „Algorithmen analysieren automatisch den Inhalt von Daten“, so Sascha Oehl weiter. Diese Informationen erweitern die Metadaten, die die Enterprise Data Management Platform per se erzeugt.
Zu den Vorteilen eines derartigen Ansatzes zählt, dass die Klassifizierungs-Engine die Analyse unstrukturierter Inhalte vornimmt und dadurch den Produktionssystemen diese Aufgabe abnimmt. Zudem unterstützt ein solches KI- und ML-basiertes System die Umsetzung von Data-Governance-Strategien: „Anwender sehen, wer wann auf bestimmte Daten zugegriffen hat. So ist beispielsweise erkennbar, wenn mehr User Zugriff auf sensible Informationen haben als vorgesehen“, erläutert Sascha Oehl. Anhand des Wertes, der den Daten entsprechend ihres Inhalts zugewiesen wurde, lassen sich personenbezogene Daten automatisch erkennen und per Richtlinie organisieren. Die Algorithmen sind zudem in der Lage, „Datenmüll“ zu erkennen und zu löschen.
„Selbstfahrender“ Speicher
Noch näher an der Infrastrukturebene angesiedelt ist der Ansatz des Flash-Storage-Spezialisten Pure Storage. Künstliche Intelligenz und maschinelles Lernen ermöglichen dem Unternehmen zufolge eine „autonom fahrende Infrastruktur“. Deren Aufgabe ist es, Daten für die Bearbeitung und Analyse möglichst effizient bereitzustellen. „Es ist somit ein Predictive Data Management erforderlich“, hebt Markus Grau hervor, Principal Systems Engineer EMEA bei Pure Storage.
Ein Schlüsselelement eines solchen Ansatzes ist ein Storage-Management-Tool mit einer KI-gestützten Analytics Engine. Das Tool stellt sicher, dass die Storage-Ressourcen bestmöglich ausgelastet sind. Zu diesem Zweck wertet Pure Storage die Datenpunkte aller Flash-Storage-Arrays aus: Log-Informationen der Hardware sowie Daten wie I/O-Zugriffe, Bandbreite, Komprimierungsraten und Informationen über die Deduplizierung. „Ein solches Storage-Management-Tool ist in der Lage, das Verhalten der Storage-Systeme und der Workloads zu erlernen, um den Normalzustand von Anomalien zu unterscheiden“, sagt Grau.
Basierend auf der Analyse historischer Daten scannt das Tool die Speicherinfrastruktur fortwährend nach bekannten Verhaltensmustern und Problemen. Administratoren erhalten automatisch Support-Tickets, um Probleme zu beheben, bevor es zu gravierenden Effekten kommt.
| Anbieter | Lösung | Einsatzfeld | Details |
| Ataccama | Ataccama ONE Platform | Datenmanagement, Datenkatalog | Plattform für „KI-gestützte Datenpflege“; Datenkatalog mit KI-Funktionen, Automatisierung und Collaboration; System wertet Nutzereingaben aus und „lernt“ daraus; Erkennen von Abhängigkeiten und ähnlichen Daten; Performance Monitoring |
| Dataiku | Dataiku Data Science Studio | Datenmanagement | Kollaborative Data-Science-Software-Plattform für Datenanalysten, Data Scientists, IT-Fachleute; Schwerpunkt auf Einführung von „Enterprise AI“ (KI-Lösungen) im Unternehmen |
| Infogix | Data 360 | Datenmanagement | Lösung für Data Governance und Data Lineage, Datenanalyse und Verbesserung der Datenqualität; Machine-Learning-Funktionen für optimierte Datenintegrität; Datenkatalog mit automatisiertem Meta-datenmanagement und Suchfunktionen mit Hilfe von Machine Learning |
| IBM | Hybrid Data Management | Datenmanagement | KI-gestütztes Datenmanagement; Erfassen und Aufbereiten von Daten unabhängig von Quelle und Struktur; Unterstützung von Hybrid- und Multi-Cloud-Umgebungen; für Datenbanken und Data Warehouses |
| Informatica | Intelligent Data Platform, Informatica MDM | Datenmanagement | Informatica MDM für Master-Datenmanagement; Data Platform für Datenmanagement, Aufbereitung und Optimierung von Daten und Schutz vor Compliance-Risiken; mit KI-Engine „Claire“; Erweiterung des Portfolios durch Übernahme von GreenBay Technologies (erweiterte KI-Funktionen für Datenintegration und Data Governance) |
| Manta | Manta Platform | Datenmanagement | Schwerpunkt auf Metadatenmanagement; Lösung erfasst alle Metadaten im Unternehmensnetz; Ermittlung der Data Lineage (Daten, aus denen aggregierte Datensätze entstanden sind) |
| MecBot | MecBot Platform | Augmented Data Management | MecSense-Technologie für automatisiertes Aufspüren von Datenmustern (Patterns) in Echtzeit; Metadatenmanagement; Nutzung von Knowledge Graphs, um Kontext von Daten zu ermitteln |
| Mindbreeze | InSpire | Datenmanagement, Enterprise Search | Enterprise Search Engine mit ADM-Elementen; Visualisieren von Kontext-Informationen; Extrahieren von Entitäten, um daraus Prozesse abzuleiten; Analyse und Verknüpfen von Daten aus diversen Quellen und Speicherorten (Cloud, Unternehmensrechenzentrum) |
| NetApp | Ontap Enterprise Data Management, NetApp Data Fabric | Datenmanagement, Enterprise Data Management | Verwaltung von Daten in Hybrid-Cloud-Umgebungen; Basis für NetApp Data Fabric für das Management von Daten am Edge, im Unternehmensrechenzentrum und in Cloud-Umgebungen; Schwerpunkt von Ontap auf Verwaltung heterogener Storage-Umgebungen; Machine-Learning- und KI-Funktionen über NetApp Active IQ verfügbar |
| Pure Storage | Pure1 | Storage-Management | KI-basiertes Tool für Storage-Management und Datenmanagement; Zielrichtung: „intelligentes“ Storage-Management als Basis für die Bereitstellung von Datenbeständen |
| Qlik | Shazam | Datenmanagement | Datenidentifikation anhand permanenter und dynamischer Suche nach Datensätzen und Ergänzungen; Berücksichtigung des Suchverhaltens des Nutzers; Änderungen durch Bearbeitung von Datensätzen wird transparent gemacht |
| SAP | SAP Data Intelligence; | Datenmanagement, Informationsmanagement | KI- und ML-unterstütztes Informationsmanagement; Identifizierung, Integration, Verfeinerung und Orchestrierung von Datenquellen; Aufbau von Data Warehouses; Einbindung von IoT-Daten; Aufbau einer zentralen Enterprise Data Fabric; Transformation und Anreicherung von Daten; durchsuchbarer Datenkatalog |
| SAS | SAS Platform, SAS Data Management | Datenmanagement | Datenmanagement und Datenintegration mit Unterstützung von Machine Learning und KI; Vorschläge für Datenoptimierung; Funktion für KI-basierte Datentransformation; Unterstützung von Usern bei Datenvorbereitung |
| Semarchy | xDM Platform | Datenmanagement | Master Data Management (MDM), Reference Data Management (RDM), Application Data Management (ADM), Data Quality und Data Governance |
| Sisense | Sisense Data and Analytics Platform | Datenmanagement, Analytics | Cloudbasierte Plattform für Business Intelligence, Datenmanagement und Analytics auf Basis von KI und Machine Learning; „Elastic Data Engine“ für die Verwaltung von Data Pipelines, Datentransformation, Advanced Analytics |
| Splunk | Splunk Enterprise | Datenmanagement, Analytics | Sammeln, Indizieren und Auswerten von Daten mittels KI und ML; automatisierte „Veredelung“ von Daten; Verwertung von Daten aus unterschiedlichen Quellen, etwa Systemen und Interaktionen |
| Stibo Systems | Stibo Master Data Management | Datenmanagement | Master-Datenmanagement, ab Version 9.2 mit Machine Learning; Schwerpunkt auf Stammdatenverwaltung (Master Data Management) von Produkten und Kunden |
| Tableau | Tableau Data Management Platform | Datenmanagement | Datenmanagement und Selfservice-Funktion; Data Preparation und Analytics; Governance-Funktionen |
| Talend | Talend Data Fabric, Data Catalog, Data Preparation, | Datenmanagement, Data Governance, Datenintegration | Tools und Plattformen für Datenintegration, Governance, Sicherstellung der Datenintegrität; Lösung für Augmented Data Integration; als Cloud-Service, Hybrid-Cloud-Lösung und für die Implementierung in Rechenzentren verfügbar |
| TCS | Machine First | Datenmanagement, Data Governance | KI-basierte Lösung für Analytics, Data Governance und Datenmanagement; Basis: Framework mit Enterprise Intelligence Platform; Bereitstellung von Daten und Informationen in Echtzeit |
| Tibco | Tibco EBX Platform | Datenmanagement, Data Governance | Management von Master Data, Referenzdaten und Metadaten; Einsatz von Machine Learning, unter anderem bei Master Data Management |
| Veritas | Enterprise Data Management Platform | Datenmanagement, Storage-Management | Infoscale-Lösung für Management von Anwendungen und Daten auf Server-Ebene; NetBackup für Datensicherung; Enterprise Vault für Archivierung; Datenanalyse-Software Data Insight für File-Systeme; Klassifizierungs-Engine für das „Veredeln“ von Daten |
| Zaloni | Arena | Datenmanagement | ADM-Plattform; mit erweitertem Metadatenmanagement; Governance-Funktion; automatisierte Integration von Daten aus diversen Quellen zu „Master Golden Records“; Optimierung von Data Pipelines; Lineage- und Datenschutzfunktion |
Tipps für den Einstieg
Doch unabhängig davon, ob ein Unternehmen ein KI-gestütztes Daten- oder Storage-Management oder Advanced-Analytics-Lösungen mit Machine-Learning-Funktionen einsetzen möchte: Wichtig ist, im Vorfeld eine schlüssige Strategie zu erarbeiten, rät Christian Leutner von Fujitsu. Es gelte dabei, vor allem die folgenden Punkte im Blick zu behalten: „Eine Basis schaffen, um alle relevanten Daten zu erhalten und die notwendigen Skills zu entwickeln.“ Außerdem sei es wichtig, KI-Lösungen in abgestufter Form einzuführen, ohne dass der Geschäftsbetrieb beeinträchtigt wird. Eine weitere Anforderung besteht darin, den Return on Investment (RoI) der KI-gestützten Datenstrategie zu ermitteln. Denn wie jede Technologie müssen sich am Ende des Tages auch ADM und Advanced Analytics für den Nutzer bezahlt machen.
Um einen schnellen Einstieg in eine KI-basierte Verwaltung und Analyse von Daten zu schaffen, bietet sich der Einsatz eines Referenzdesigns an. Es sollte KI-Frameworks, mathematische Funktionsbibliotheken und eine Data Fabric mit Storage-Ressourcen und Compute-Clustern enthalten. Eine solche Data Fabric hat beispielsweise NetApp entwickelt, ebenso wie die Datenmanagement-Lösung Ontap.
Auf einen weiteren wichtigen Punkt weist Sofiane Fessi von Dataiku hin: das Zusammenspiel von Augmented Data Management und MLOps (Machine Learning Operations). Dies ist gewissermaßen ein DevOps-Ansatz (Development Operations) für Machine Learning. Er sieht eine enge Zusammenarbeit von Data-Science-Fachleuten, Fachbereichen und IT-Teams vor, um die Entwicklung und Bereitstellung von Machine-Learning-Modellen und Datenapplikationen zu beschleunigen. „Ein Augmented Data Management ohne MLOps bleibt Stückwerk – und vice versa“, sagt Fessi. Negative Effekte seien vor allem bei der Implementierung und dem Management von Datenmanagement-Anwendungen in Produktionsumgebungen zu erwarten. Das könne dazu führen, dass sich die Investitionen in eine Dateninfrastruktur und entsprechende Fachleute nicht auszahlen.
Der Fachmann plädiert daher für einen „kollaborativen“ Ansatz: Mitarbeiter aus den Fachbereichen, IT-Experten, Datenspezialisten und Entwickler von KI- und ML-Lösungen benötigen ein Tool, um gemeinsam Anwendungen für das Management und die Analyse von Daten zu erstellen und einzusetzen. „Zwar arbeiten bereits heute unterschiedliche Teams bei KI-Projekten zusammen, doch fehlte bislang eine zentrale Collaboration-Lösung für alle Projektteilnehmer.“ Eine solche Plattform hat das französische Unternehmen mit dem Dataiku Data Science Studio entwickelt.
Fazit & Ausblick
Maschinelles Lernen und Künstliche Intelligenz sind nicht nur bei der Analyse von Informationsbeständen unverzichtbar, sondern auch beim Aufbereiten, Speichern und Management von Daten. Ein Grund ist, dass digitale Geschäftsmodelle eine solide Datenbasis benötigen. Zeitverzögerungen und Fehler durch manuelle Prozesse müssen daher ausgeschlossen werden.
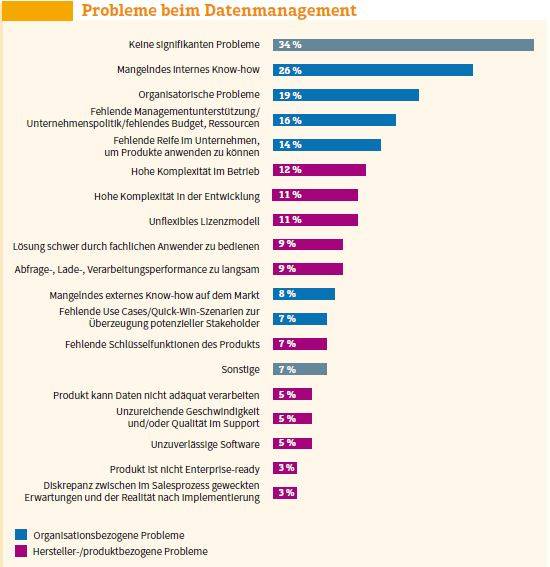
Allerdings sollten Anbieter von Datenmanagement-Lösungen nicht unterschätzen, dass ein beträchtlicher Teil der Nutzer noch nicht allzu viel mit Ansätzen wie Advanced Analytics und KI-unterstützten Data-Management-Lösungen anfangen kann. Das ist ein Ergebnis der Studie „The Data Management Survey 20“ des Analystenhauses BARC. So stufen zwar 37 Prozent der Anbieter KI- und Machine-Learning-Funktionen als wichtig ein, aber lediglich 10 Prozent der Anwender.
Stattdessen sehen sich die Unternehmen mit profanen Herausforderungen konfrontiert, beispielsweise dem Mangel an internem Know-how (26 Prozent), organisatorischen Problemen (19 Prozent) oder fehlender Reife im Unternehmen (14 Prozent). „Der Aufbau der erforderlichen Kompetenzen scheint ein allgemeines Problem zu sein, das für einige Unternehmen nicht vollständig durch externe Ressourcen abgedeckt werden kann“, kommentiert Timm Grosser, Senior Analyst Data & Analytics bei BARC. „Im Moment besteht eine deutliche Diskrepanz zwischen dem grundsätzlichen Potenzial durch den Einsatz von Software und dem Mehrwert, der mit ihr in der Realität erzielt wird.
“Es reicht folglich nicht aus, „mal eben schnell“ neue Technologien wie Augmented Data Management einzuführen. Vielmehr muss das Gesamtpaket stimmen. Und dazu gehören neben KI-Algorithmen auch Menschen, deren Wissen und deren Arbeitsumgebung. Die Technik allein kann es nicht richten.
Im Gespräch mit Wolfgang Kobek von Qlik
Benötigen Anwender ein KI-gestütztes Datenmanagement, also ein Augmented Data Management, oder ist ADM nur ein weiteres Marketing-Schlagwort? Wolfgang Kobek, Vice President EMEA beim Datenanalyse-Spezialisten Qlik, ist sich sicher: Künstliche Intelligenz spielt eine zentrale Rolle bei dem Prozess, der Rohdaten in verwertbare Informationen verwandelt.

com! professional:Welche Elemente zählen aus Ihrer Sicht zu Augmented Data Management?
Wolfgang Kobek: Dem Begriff des ADM entspricht am ehesten der „Raw to Ready“-Ansatz. Darunter verstehen wir die Datenbereitstellung, von den Rohdaten bis hin zu den analysebereiten Informationen. Dieser oft weniger sichtbare, aber sehr arbeitsintensive Teil der Datenwertschöpfungskette sorgt dafür, dass aus heterogen und teils weit verteilten Rohdatenquellen verwertbare Informationsquellen für alle Arten von Datenanalysen werden.
Direkt angebundene Echtzeit-Datenquellen können hier ebenso betrachtet werden wie strukturierte Data Warehouses oder unstrukturierte Data Lakes.
com professional: Und warum kommt dabei KI ins Spiel?
Kobek: Vor diesem Hintergrund hat es auf jeden Fall Sinn, das Datenmanagement mit KI-Unterstützung zu optimieren. Denn gerade beim Suchen, Identifizieren und Überprüfen von Daten-Sets, etwa auf ihre Vollständigkeit und ihr Format hin, ist eine KI-Instanz manuellen Prozessen überlegen und kann die Fehleranfälligkeit deutlich reduzieren. Das ist möglicherweise erfolgskritisch für Analyseprojekte. Denn Fehler, die bei der Aufbereitung und Bereitstellung der Daten gemacht werden, lassen sich in der Analyse nicht mehr korrigieren.
com! professional:Ist es überhaupt sinnvoll, einen Begriff wie ADM einzuführen?
Kobek: Mittel- und langfristig gesehen sicher. Auch von Augmented Intelligence beziehungsweise Augmented Analytics sprechen wir aus gegebenem Anlass bereits seit einiger Zeit und haben entsprechende Funktionen mit an Bord. Beim Management von Daten dauert es womöglich noch ein wenig, bis der Augmented-Ansatz so geläufig ist wie beim Thema Analytics. In der Analyse-Erfahrung ist für viele Anwender der Nutzen von KI verständlicherweise sichtbarer als bei der Bereitstellung von Daten.Zudem stellen sich bei der Data Preparation andere Fragen mit Blick auf einen KI-Einsatz. Das hängt stark vom jeweiligen Anwendungsfall ab. Soll eine KI zum Beispiel fehlerhafte Datensätze nur benennen oder auch automatisiert korrigieren? Ergibt das überhaupt Sinn? Und wenn ja, in welchem Toleranzbereich?
com! professional:Wie bewertet Qlik generell den Einsatz von KI und Machine Learning bei der Analyse von Daten?
Kobek: Bei der Analyse von Daten lernen intelligente Systeme bereits viel und auch sehr effektiv. Nutzer- und Abfrageverhalten spielen dabei ebenso eine Rolle wie KI-unterstützte Vorschläge für mögliche Anschlussfragen in einem Analyseprozess oder ideale Visualisierungen. Hier kommen die KI-Technologien vor allem in Form von höherem Komfort, als Beschleuniger für die Kontextfindung oder als Visualisierungshilfe zum Zug. Bei der Datenbereitstellung kann eine KI-Instanz zum Beispiel dabei helfen, schnell und vollständig mögliche Fehler oder Lücken in Datensätzen zu finden.
com! professional: Wie sind der Status und die Akzeptanz von KI-basierten Ansätzen im Bereich ADM und Augmented Analytics in Unternehmen und bei Anwendern zu bewerten?
Kobek: Das Thema Augmented – also durch KI-Fähigkeiten unterstützt – versteht Qlik als Ergänzung, nicht als Ersatz menschlicher Fähigkeiten in der gesamten Data- und Analytics-Journey. Im Bereich Analytics ist dieser Trend den Unternehmen schon bewusst: Sie erkennen die Vorteile eines komplementären Wirkens von KI-unterstützter Analyse und menschlicher Intuition. Andere Teile des Data-Lifecycles, meist diejenigen, die der Analyse vorgelagert sind, sind im Alltag eines Standard- oder auch Power-Users zwar eher versteckt, können aber auch von KI-Unterstützung profitieren, etwa beim Sichern der Datenqualität oder beim Erkennen von Zusammenhängen zwischen heterogenen Datensätzen. Qlik setzt aus diesem Grund auf eine ganzheitliche „Data to Insights“-Perspektive. Das heißt, dass von den Rohdaten bis hin zur konkreten, umsetzbaren Geschäftsentscheidung eine Datenstrategie hinter jedem datengetriebenen Prozess steckt.
com! professional:Zahlt sich eine solche Strategie denn auch finanziell aus?
Kobek: Auf jeden Fall. Das belegt eine Studie von Qlik und IDC. Ihr zufolge erzielen Unternehmen mit einer starken „Daten-Pipeline“ rund 17 Prozent mehr Umsatz und Gewinn.









Be the first to comment