
In diesem Kapitel des Tagebuchs wird der Hype um ChatGPT genauer unter die Lupe genommen. [...]
1 – Wer kennt ChatGPT?
Der Hype um künstliche Intelligenz (KI) reißt nicht ab, und wird aktuell von ChatGPT angeführt. Mit der aktuellen Version GPT-4 wurde der Chatbot noch intelligenter und kann weitere Aufgaben im Alltag übernehmen.
ChatGPT (Generative Pre-trained Transformer) ist ein Prototyp eines Chatbots und ist somit ein Textroboter. Ein Chatbot ist die Benutzerschnittstelle ein textbasierten Dialogsystems , die auf maschinellem Lernen beruht. Er wurde vom US-amerikanischen Unternehmen OpenAI entwickelt und im November 2022 veröffentlicht.
Tatsache ist, dass viele Menschen den Textroboter ChatGPT schon heute im Alltag nutzen, als wäre es nie anders gewesen. Kann aus Sicht des Datenschutzes zu einem Problem werden?
Im Wesentlichen basieren die, in diesem System angewendeten KI-Algorithmen auf Methoden, die den Textroboter durch Beispiele lernen lassen. Dabei werden anhand des Trainings immer mehr sinnvolle Text in das System eingebracht und miteinander verknüpft. Wenn in den Texten personenbezogene Daten vorkommen, sollte dem Benutzer von ChatGPT bewusst sein, dass diese Lernergebnisse auch anderen Benutzern bereitgestellt werden können.
2 – Kann ChatGPT Zeit sparen?
2.1) Qualität der Wissensbasis und Weiterentwicklung
ChatGPT wirbt mit dem Versprechen, die Arbeit von nicht so Wichtigem zu befreien und rasch Ergebnisse zu liefern. Dies ist verlockend, denn man spart Zeit und kann sich auf die wesentlichen Punkte seiner Arbeit fokussieren. Dem Anwender sollte jedoch klar sein, dass bspw. durch die Chatbot-Übersetzung einer E-Mail aus seinem Berufsleben, er gleichzeitig die KI mit einer Menge Daten füttert, die sowohl personenbezogene als auch firmensensible Daten enthalten können. Auch diese Informationen werden vom Chatbot (wie ChatGPT) genutzt, um noch mehr zu lernen und damit „sein“ Wissen weiterzuentwickeln.
Ein wesentlich bestimmender Faktor für die Qualität der Wissensbasis sind die Anzahl der Anwender, da diese sie Anzahl der Fragen bestimmen. Mit neuen Fragen wird dabei immer wieder neue Information in Form von sogenannten Trainingssamples in das „selbstlernende System“ eingebracht.
Die nachfolgende Grafik zeigt eindrucksvoll, dass nach der Veröffentlichung im November 2022 ChatGPT innerhalb von 5 Tagen (!) nach Veröffentlichung bereits eine Million Nutzer registriert waren. Im Jänner wurde die Anzahl bereits auf 100 Millionen und heute wird sie auf 500 Millionen geschätzt. Kein anderer Internetdienst kann eine derartig rasante Entwicklung der Nutzerbasis vorweisen.
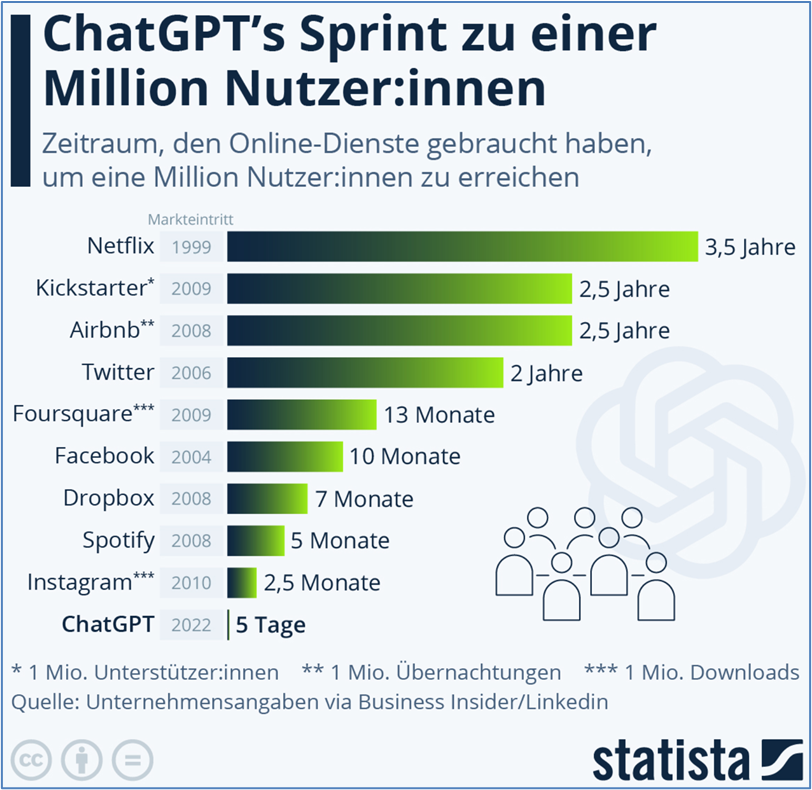
(Quelle: https://de.statista.com/infografik/29195/zeitraum-den-online-dienste-gebraucht-haben-um-eine-million-nutzer-zu-erreichen/)
Auf Grund dieser unglaublichen Anwenderzahlen geht die Weiterentwicklung des Wissens so rasant vorwärts. Dabei werden die neuen Informationen genutzt, um nachfolgenden Fragestellungen von Anwendern noch bessere Antworten zu liefern. Dies ergibt, dass die Qualität der Antworten tatsächlich immer besser wird, was wiederum zu einer Verbesserung der Akzeptanz bei den Anwendern führt.
2.2) Sind die gelernten Daten in Sicherheit?
Eine hochkarätige Forschergruppe, die sich aus Mitarbeitern von Google, Stanford, UC Berkeley, Northeastern University, OpenAI, Harvard und Apple zusammensetzte, testeten Attacken auf sogenannte GPT-2 Modelle auf denen auch ChatGPT basiert. Überraschendes Ergebnis:
Den Forschern gelang es durch entsprechende Fragestellungen, die personenbezogenen Daten dem System wieder zu entlocken.
So gelang es dem Team, hunderte Sequenzen aufs Wort genau dem GPT-2 System wieder zu entlocken. Dazu gehörten auch Telefonnummern, Mailadressen, Unterhaltungen oder auch Programmcodes.
Für Interessierte sei an dieser Stelle auf die Veröffentlichung des Ergebnisses der Forschergruppe mit dem Titel: Extracting Training Data from Large Language Models verwiesen. Daran wird sowohl das Befüllen des Chatbots mit Trainingsdaten durch „Internet-Crawling“ (Suchmaschinen mit maschinellem Lernen) über potenzielle Attacken bis zur Umsetzung der Fragestellungen der Systemaufbau nachvollzogen.
Im Klartext bedeutet das: Wenn Sie personenbezogene Daten bzw. sensible Unternehmensdaten eingeben, ist es wahrscheinlich nur eine Frage der Zeit, dass es Dritten mit entsprechenden Angriffswerkzeugen gelingen wird, darauf zugreifen. Diese extrahierten Informationen können anschließend gegen den Einzelnen oder auch gegen das Unternehmen zur Anwendung kommen.
2.3) Praktisches Beispiel: „Textübersetzung Englischà Deutsch“
Um die Möglichkeiten zu verdeutlichen haben wir von ChatGPT den englischen Abstract des Ergebnisses der zuvor aufgelisteten Forschergruppe ins Deutsche übersetzen lassen und in Vergleich zu einer Übersetzung mit dem bekannten Programm DeepL gesetzt.

Die in Abbildung 2 dargestellte Frage besteht aus 2 Teilen. Im ersten Teil wird in Grün die Anweisung formuliert einen Text zu übersetzen und anschließend wird der zu übersetzende Abstract des Artikels in Gelb dargestellt. Das Ergebnis der ChatGPT Übersetzung ist in Abbildung 3 in Grün dargestellt:

In Abbildung 4 ist in Orange das Ergebnis der Übersetzung mit DeepL (https://www.deepl.com/translator) ausgeführt.

Die Autoren sind überrascht, dass das ChatGPT Ergebnis ähnlich gute Ergebnisse liefert, wie der Übersetzungsspezialist DeepL. An diesem einfachen Beispiel lässt sich das Potential dieser KI-Entwicklung einfach nachvollziehen.
3 – Vertrauliche Daten haben in ChatGPT nichts verloren!
Generell sollte die Regel befolgt werden, dass personenbezogene oder vertrauliche Daten in ChatGPT nichts verloren haben, zumindest nicht im „Klartext“.
Dies bedeutet aus Sicht des Datenschutzes, dass man zumindest eine Technisch-Organisatorische-Maßnahme (TOM) vorsieht, die diese Informationen vor dem Einfüllen in einen ChatBot pseudonymisiert. Somit kann ChatGPT diese nicht wieder in „Klartext“ umwandeln.
Der Anwender des Chatbots kann auf Grund der Schlüsselkenntnis und der Kenntnis der Pseudonymisierung die Ergebnisse wieder in den entsprechenden „Klartext“ wieder umwandeln.
Ein einfaches Beispiel bei Anwendung der Funktionalität „Übersetzen einer E-Mail mit Namensnennung“ für Pseudonymisierung ist gegeben, wenn der in der E-Mail enthaltene reale Namen vor der Übersetzung durch „Mustermann/frau“ ersetzt wird. Dann ist es der KI klarerweise unmöglich weitergehende Informationen der E-Mail der natürlichen Person zuzuordnen und mit bereits eingefüllten Informationen weitere zu verknüpfen, da der Schlüssel „realer Name“ gar nicht vorhanden ist. Der Anwender erhält jedoch das gewünschte Ergebnis „die Übersetzung“ retour und ersetzt Mustermann/frau wieder mit den „realen“ Namen.
4 – Schlussbemerkung
Es ist überraschend, wie schnell die neue KI auch von technisch nicht versierten Menschen angenommen und eingesetzt wird. Zum heutigen Zeitpunkt lässt sich nicht abschätzen, in welche Richtung das Führen wird und wie die eingegebenen Daten verarbeitet werden.
Aus unserer Sicht gilt die Regel:
Niemals sensible Informationen über sich selbst oder Ihre Unternehmen weiterzugeben, sonst könnten diese entweder durch Zufall oder ganz gezielt veröffentlicht bzw. zu kriminellen Zwecken als neuer Angriffsvektor eingesetzt werden.
Das Tagebuch wird zur Verfügung gestellt von:

DSGVO-ZT GmbH









Be the first to comment