
Das Forschungsteam für Security and Privacy an der TU Wien erklärt die Herausforderungen beim Programmieren einer Contact-Tracing-App für COVID-19-Fälle. [...]
Die Idee klingt einfach: Fast jeder trägt heute ein Smartphone mit sich herum. Wenn alle Smartphones ständig registrieren, welche anderen Smartphones in ihrer Nähe sind, dann können bei einer neu diagnostizierten COVID-19-Erkrankung alle Leute automatisch gewarnt werden, die in letzter Zeit mit der erkrankten Person in Kontakt waren.
Im Detail ist die Sache freilich ein bisschen komplizierter: Derzeit wird weltweit intensiv über unterschiedliche technische Lösungen diskutiert – Datenschutz spielt dabei genauso eine Rolle wie der Schutz vor Coronaviren. Die Informatikerin Clara Schneidewind hat sich die Sicherheitsaspekte solcher Contact-Tracing Apps angesehen.
Zentral oder dezentral?
„Wenn Contact-Tracing wirklich funktionieren soll, dann muss es international betrieben werden“, sagt Clara Schneidewind aus der Security-and-Privacy-Forschungsgruppe am Institut für Logic and Computation der TU Wien. „Daher wurde das europäische Konsortium PEPP-PT ins Leben gerufen. Es soll keine einzelne App entwickeln, sondern sich auf eine gemeinsame Schnittstelle einigen, damit verschiedene Apps miteinander interagieren können.“ Wegen Meinungsverschiedenheiten spaltete sich allerdings ein Teil davon ab und ist jetzt unter dem Namen „DP-3T“ aktiv.
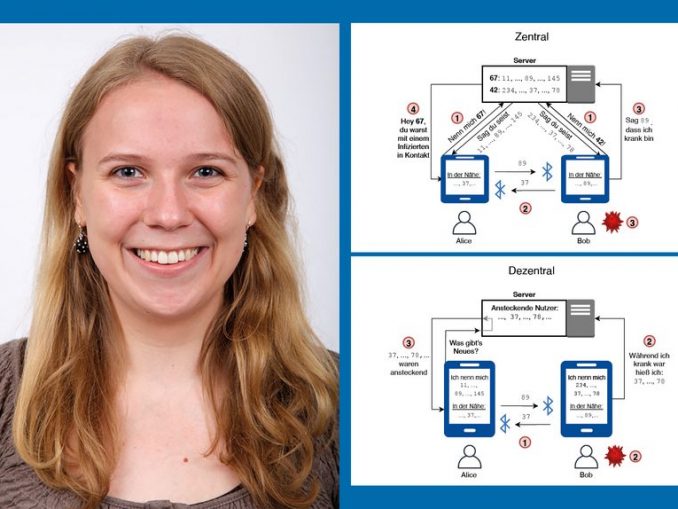
Beim Entwickeln solcher Schnittstellen muss eine wichtige Grundsatzentscheidung getroffen werden: Soll man einen zentralen Ansatz verfolgen, bei dem die wichtigsten Daten auf einem Server gespeichert werden, oder ist ein dezentraler Ansatz besser, bei dem möglichst wenige Daten zentral erfasst werden?
„Beim zentralen Ansatz bekommt jeder User eine ID am Server, zusätzlich bekommt er vom Server immer wieder zufällig generierte, temporäre Pseudonyme zugewiesen“, erklärt Clara Schneidewind. „Diese Pseudonyme werden von den Smartphones untereinander ausgetauscht.“ Wenn jemand positiv auf COVID-19 getestet wird, dann werden alle temporären Pseudonyme, mit denen in letzter Zeit ein Kontakt registriert wurde, auf den Server hochgeladen. Dort kann nachgeschlagen werden, welche Personen jeweils zu diesen Pseudonymen gehören, und diese Personen werden gezielt benachrichtigt.
Beim dezentralen Ansatz verteilt der Server keine Pseudonyme, sie werden lokal am eigenen Smartphone generiert. Wird man positiv getestet, dann lädt man alle selbstgenerierten Pseudonyme auf einen Server, die man in letzter Zeit verwendet hat. Andere User können dann regelmäßig die Liste der Pseudonyme infizierter Personen vom Server laden und dann anhand der eigenen Kontaktliste überprüfen, ob sie Kontakt mit einer dieser Pseudonym-Codes hatten.
Nutzen und Risiko: Vieles ist Abwägungssache
„Welche Variante besser ist, kann man nicht so eindeutig sagen. Letztlich ist es immer eine Abwägung von Funktionalität und Privatsphäre. Meine persönliche Einschätzung ist, dass die Privatsphäre beim dezentralen Ansatz deutlich besser gewahrt bleibt“, sagt Clara Schneidewind. „Informationen über nicht infizierte Personen werden bei einer dezentralen Architektur nie an den Server geliefert, es gibt keine zentrale Stelle, die etwas über Interaktionen zwischen den Usern erfährt.“
Allerdings könnte man auch argumentieren, dass das Sammeln von Daten positive Seiten hat: Für die epidemiologische Forschung wäre es hilfreich, realistische Kontakt-Netze analysieren zu können. „Je mehr Daten offengelegt werden, desto mehr lässt sich daraus ableiten – im Guten wie im Schlechten“, sagt Clara Schneidewind. „Daher gibt es auch bereits Überlegungen über freiwillige Datenspenden: Man kann ganz bewusst bestimmte Informationen zugänglich machen – nicht für staatlich kontrollierte Server, sondern beispielsweise für ausgewählte Forschungseinrichtungen.“
Unterstützung durch Google und Apple wäre hilfreich
Eines der großen Probleme bei der Entwicklung von Contact Tracing Apps ist, dass man die großen Software-Giganten Google und Apple an Bord holen muss. „Die Stopp-Corona-App des österreichischen Roten Kreuzes war eine der ersten Contact-Tracing-Apps in ganz Europa. Sie hatte allerdings mit einer großen technischen Herausforderung zu kämpfen“, sagt Clara Schneidewind. „Diese App führt im Fall einer Begegnung ein kompliziertes Protokoll aus, den sogenannten Handshake. Die Smartphone–Betriebssysteme von Google und Apple erlauben es allerdings nicht, dass dieser Handshake automatisch im Hintergrund ausgeführt wird. Man muss den Handshake explizit bestätigen. Das macht die App etwas umständlich.“
Mit simpleren Protokollen, wie sie von europäischen Konsortien nun vorgeschlagen werden, wird die Sache zwar etwas einfacher, aber immer noch besteht das Problem, dass die App idealerweise permanent im Hintergrund laufen sollte – auch wenn sie nicht geöffnet ist. „Insbesondere im Fall von iOS, dem Apple-Betriebssystem, müsste man dafür eine spezielle Genehmigung für Contact-Tracing-Apps erteilen“, erklärt Clara Schneidewind. „Wenn Google und Apple hier von sich aus Erleichterungen schaffen würden, könnte man die Entwicklung von Contact-Tracing-Apps erheblich erleichtern. Erfreulicherweise wird bei den beiden Unternehmen daran bereits gearbeitet.“
Eine ausführlichere Darstellung dieses Themas finden Sie hier in dem sehr lesenswerten und informativen Blogbeitrag von Clara Schneidewind.









Be the first to comment