
Zugegeben, Schlagworte wie „Unternehmen sitzen auf einem Datenschatz“ wurden in den vergangenen Jahren überstrapaziert. Doch in der Tat nehmen die Datenbestände in Firmen und öffentlichen Einrichtungen rapide zu. [...]

Das zeigt die Studie „Worldwide Global Datasphere Data Forecast 2021-2026“ des Marktforschungsunternehmens IDC. Sie prognostiziert, dass allein das Volumen der unstrukturierten Daten, die weltweit vorhanden sind, zwischen 2023 und 2026 von 115 auf über 200 Zettabyte anwächst. Die Menge der strukturierten Daten soll sich in dieser Zeitspanne fast verdreifachen, von 7,6 auf 21 Zettabyte.
Ein Großteil der Unternehmen hat erkannt, welches geschäftliche Potenzial in diesen Informationsbeständen steckt. So nutzen beispielsweise in Deutschland rund 80 Prozent Daten für die Wertschöpfung. Fast alle (90 Prozent) stufen sich als „datenorientiert“ ein. Das ergab die Analyse „Data-Driven Enterprise 2023“ von IDG Research Services.
Doch die Realität sieht häufig anders aus. Daten zu erfassen, zu konsolidieren und in verwertbare Erkenntnisse umzusetzen (Insights), oder sie gar für neue Geschäftsmodelle zu nutzen, stellt Unternehmen vor große Herausforderungen. So bewertet die Hälfte der Unternehmen, die IDG befragte, das Management und die Qualität der vorhandenen Daten als unzureichend.
Und das Beratungshaus Bearingpoint hat auf Basis der Erkenntnisse aus Tausenden von Projekten ermittelt, dass mehrere Faktoren nötig sind, damit Unternehmen ihren „Datenschatz“ heben können. Dazu zählen Kenntnisse der eigenen Datenwelt und die Vorbereitung der Mitarbeiter auf datenorientierte Prozesse, und dies in Verbindung mit dem Einsatz von neuen Technologien.
„Data Mesh ist ein Ansatz für den dezentralen Umgang mit Daten und Analysen, um Agilität und Flexibilität für Unternehmen als Ganzes zu erreichen.“
Benjamin Bohne – Group VP Sales CEMEA bei Cloudera
„Ein Verständnis über die zielgerichtete Datennutzung ist unabdingbar, um neue Datenprodukte anbieten zu können. Dies setzt allerdings eine klare Datenstrategie und umfangreiche Data Governance voraus“, unterstreicht Tomas Chroust, der als Partner bei Bearingpoint für die Schweiz zuständig ist.
Neuer Ansatz: Data Mesh
Um Daten zu „mobilisieren“ und nutzbar zu machen, etabliert sich neben Datenplattformen, Datenmanagementlösungen, Data Fabrices und DataOps ein weiterer Ansatz: Data Mesh. Die Grundidee hat die IT-Spezialistin Zhamak Dehghani vor einigen Jahren beim Technologieberatungshaus Thoughtworks entwickelt. Heute ist sie CEO von Nextdata, das mit Nextdata OS ein Toolset entwickelt hat, mit dem Anwender ein Data Mesh einrichten können.
Doch was verbirgt sich hinter diesem Begriff? Jedenfalls keine Lösung von der Stange, so Benjamin Bohne, Group Vice President Sales CEMEA bei Cloudera: „Data Mesh ist ein Ansatz für den dezentralen Umgang mit Daten und Analysen, um Agilität und Flexibilität für Unternehmen als Ganzes zu erreichen.“
Ein domänenorientiertes Design überträgt den Datenbesitz von einer zentralen Instanz im Unternehmen auf einzelne Teams oder Geschäftsbereiche. „Diese sind nicht nur für ihre Daten verantwortlich, sondern auch dafür, wie diese Daten im Unternehmen genutzt werden können“, ergänzt Genevieve Broadhead, Principal for Retail EMEA im Industry Solutions Team bei MongoDB.
Vier Grundelemente
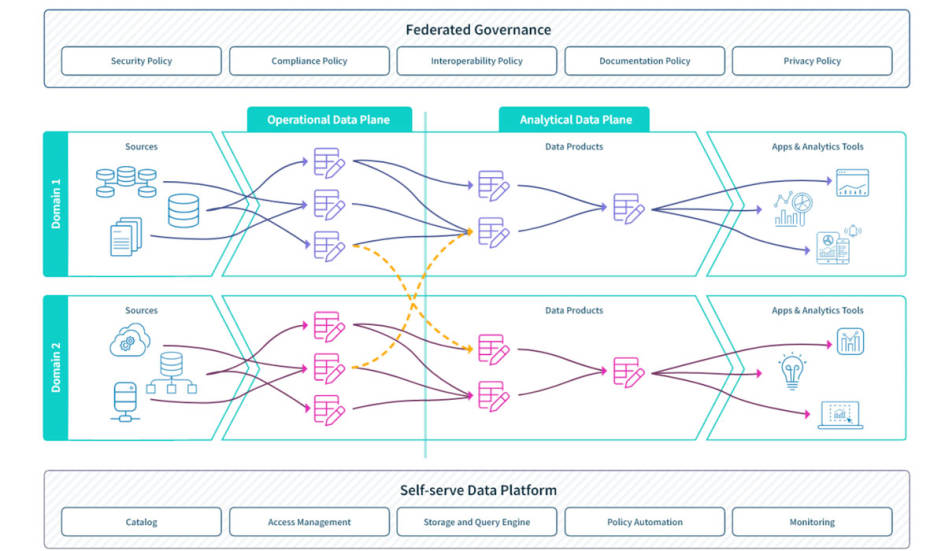
Ein Data Mesh setzt gemäß der Definition von Zhamak Dehghani auf vier Säulen auf. Die erste ist die domänenbasierte Data Ownership. Das heißt, die Kontrolle über die Daten wird von zentralen Datenteams auf Domänen verlagert, die mit bestimmten Daten am besten vertraut sind, etwa Fachbereiche wie Vertrieb, Produktentwicklung oder Finanzwesen.
„Die Fachbereiche wissen schließlich am besten, wie diese Informationen verwaltet und bereitgestellt werden sollen und welche Zugriffsparameter sinnvoll sind“, betont Marc Kleff, Director Solutions Engineering bei NetApp Deutschland. „Das ist das Mesh-Prinzip: Wer die Daten erzeugt, trägt Mitverantwortung.“
Diese Verantwortung umfasst auch die IT-Ressourcen der Domäne. Deshalb bestehen Domain-Teams aus Mitarbeitern der Fachabteilungen und IT-Fachleuten.
„Data Mesh hat zwei Vorteile. Erstens ist das Geschäftsteam Dateneigentümer, das die Daten am besten versteht (…). Zweitens sind die Daten im gesamten Unternehmen zuverlässig verfügbar (…).“
Genevieve Broadhead – Principal for Retail EMEA, Industry Solutions Team bei MongoDB
Das zweite Element sind Datenprodukte, Stichwort „Data as a Product“. Das heißt, Daten werden über die Grenzen von Domänen hinweg anderen Nutzern („Kunden“) zur Verfügung gestellt, etwa Fachleuten in anderen Abteilungen oder Data Scientists. Diese Datenprodukte müssen mehrere Anforderungen erfüllen, etwa in Bezug auf die Vertrauenswürdigkeit, Interoperabilität, Sicherheit und Ausstattung mit Schnittstellen. Wichtig, ist zudem, dass Kunden solche Datenprodukte auf einfache Weise finden können. Dies lässt sich mithilfe von Metadaten erreichen.
Self-Service und Federated Governance
Damit Teams über die Grenzen von Abteilungen und Domänen hinweg Datenprodukte bereitstellen, pflegen und nutzen können, ist außerdem eine Datenplattform erforderlich, die nach dem Selbstbedienungsmodell funktioniert. Diese Plattform stellt Services und APIs (Application Programming Interfaces) zur Verfügung. Die vierte Säule ist eine „Federated Computational Governance“. Das bedeutet, die Domänen-Teams entwickeln gemeinsam ein übergreifendes Data-Governance-Modell für die Datenprodukte. Dieses berücksichtigt beispielsweise Datenschutzregelungen und lässt sich an geänderte Vorgaben anpassen. Zusätzlich definieren die Data Owner Richtlinien für ihre Datenprodukte.
Vorteile von Data Meshs
Bereits diese Basiselemente machen deutlich, dass die Implementierung eines Data-Mesh-Ansatzes mit einem nicht zu unterschätzenden Aufwand verbunden ist. So müssen Organisationsstrukturen umgebaut und Aufgaben neu verteilt werden. Daher gilt es abzuwägen, ob sich der Aufwand lohnt. Für Genevieve Broadhead steht das außer Frage: „Data Mesh hat zwei Vorteile. Erstens ist dasjenige Geschäftsteam Dateneigentümer, das die Daten am besten versteht und somit die Möglichkeit hat, sie zu ändern und zu erneuern. Zweitens sind die Daten im gesamten Unternehmen zuverlässig verfügbar, so dass sie für viele andere betriebliche und analytische Anwendungsfälle genutzt werden können“, etwa um Innovationen und die Digitalisierung voranzutreiben.
Ein weiterer Pluspunkt ist, dass das dezentrale Konzept Flaschenhälse beseitigt: „Es entstehen keine Engpässe durch die Zentralisierung von Betrieb, Eigentum und Verwaltung von Daten und Analysen“, unterstreicht Benjamin Bohne von Cloudera. Hinzu kommt, dass Fachleute die Aufgabe übernehmen, Daten und Erkenntnisse zu erstellen und als Produkte bereitzustellen. „Daher werden sie nicht als Daten wahrgenommen, sondern als Projekt. Das führt zu eine verbesserten Langlebigkeit und Qualität sowie einem höheren Wert.“
(Quelle: Qlik)
Mit einem Data Mesh soll zudem ein Nachteil herkömmlicher Dateninfrastrukturen überwunden werden: dass Daten in separaten Silos abgelegt werden. Dies führt sonst oft zu einem höheren Bedarf an Storage-Ressourcen und verhindert eine übergreifende Sicht auf Informationen. Dadurch wiederum ist es schwieriger, Daten aus unterschiedlichen Silos zu kombinieren und zu analysieren. Dies kann zu Lasten der Reaktionsfähigkeit und Time-to-Market-Zeiten von Unternehmen und deren Entwicklungsabteilungen gehen.
Allerdings weisen Kritiker darauf hin, dass auch das Domänen-Modell eines Data Mesh dazu führen kann, dass abgeschottete Bereiche entstehen. Hinzu kommt, dass es möglicherweise zu einem Wildwuchs in Bereichen wie der Datenspeicherung und dem Data Management kommt. Dies ist dann der Fall, wenn viele Data Stores und APIs zum Einsatz kommen. Dann steigt der Aufwand für die Verwaltung und damit die Belastung der zuständigen IT- und Datenspezialisten. Und dies ist angesichts des Mangels an solchen Fachleuten etwa in Deutschland und der Schweiz problematisch.
„Um Data Mesh im Unternehmen einzusetzen, muss das bisher zentral vorhandene technische Spezialwissen auf die Business Units verteilt werden. Diese Anpassung stellt für kleinere Unternehmen, die hier teilweise unterbesetzt sind, eine große Herausforderung dar“, bestätigt Till Sander, Chief Technology Officer beim Business-Intelligence-Beratungshaus Areto Consulting in Köln.
Dezentralisierte Datenbestände stellen zudem nach seinen Erfahrungen erhöhte Anforderungen an die Auffindbarkeit und Dokumentation von Informationen. „In diesem Zusammenhang ist der Einsatz eines Data Catalog unerlässlich.“
Die Rolle von Data Fabrics
Im Zusammenhang mit der Debatte über Data Meshs drängst sich vielen Unternehmen unweigerlich eine weitere Frage: Was soll eine Firma tun, die bereits viel Geld und Ressourcen in Lösungen wie Data Fabrics und Data Lakes investiert hat? Die gute Nachrichtig lautet: Storage- und Datenspezialisten sind sich darin einig, dass sich diese Technologien mit einem Data Mesh verbinden lassen.
„Entscheidend ist, dass Daten genau dort abgerufen, analysiert und verarbeitet werden können, wo sie benötigt werden.“
Remko Deenik – Technical Director Europe bei Pure Storage
„Technisch gesehen verfolgt Data Mesh einen dezentralen Ansatz, bei dem die Umsetzung einzelnen Teams überlassen bleibt. Data Fabric orientiert sich an der Idee des klassischen zentralen Data Warehouse, ergänzt diese aber durch ‚moderne‘ Building Blocks, etwa Data Pipelines und Data Lakes“, erläutert Till Sander. Daher könne ein Data Mesh durchaus als „Governed Mesh“ auf Basis einer zentralen Plattform entwickelt werden, bei der die Teams auf einer Data Fabric mit dem gleichen Technologieportfolio arbeiten.
Technische Basis und Storage
Auch Cloudera plädiert für ein „Sowohl als auch“ von Mesh und Fabric. Bei beiden Ansätzen sei das Datenmanagement das Herzstück. Es gibt jedoch nach Einschätzung von Benjamin Bohne auch Unterschiede: „Eine Data Fabric erschließt Daten in großem Umfang, stellt sie in einen geschäftlichen Kontext und macht sie auf sichere und konforme Weise als Self-Service verfügbar. Data Mesh baut dagegen auf dem Wissen auf, das aus allen Datenquellen gesammelt wurde, um die Daten entlang der Domänen bereitzustellen und jeden Datensatz auffindbar zu machen“. Data Mesh sei ohne ein tiefes Datenverständnis und angemessene Data Governance, also eine Data Fabric, nicht möglich.
Zum selben Ergebnis kommt NetApp-Fachmann Marc Kleff, insbesondere vor dem Hintergrund, dass Daten sowohl im Unternehmens-Datacenter als auch in Cloud-Umgebungen gespeichert werden. „Eine Data Fabric ist ein Architekturkonzept für die hybride Multi-Cloud-Welt. Das heißt, sie optimiert Anwendungsfälle wie Data Protection, Daten-Tiering, Produktivdatenbereitstellung, Security und Compliance sowie die Multi-Cloud-Nutzung. Damit bildet die Data Fabric das Fundament für Data-Mesh-Ansätze.“
Apropos Fundament: Wer Data Fabrics oder Meshs einsetzen möchte, sollte bei der Planung prüfen, ob die Storage-Ressourcen für solche Konzepte ausgelegt sind. „Entscheidend ist, dass Daten genau dort abgerufen, analysiert und verarbeitet werden können, wo sie benötigt werden. Dies erfordert Datenmobilität, etwa die Fähigkeit, Anwendungen mit ihren Daten von einem Cloud-Anbieter zu einem anderen zu verschieben“, sagt Remko Deenik, Technical Director Europe beim Storage-Anbieter Pure Storage.
Zudem muss es möglich sein, auf alle Daten zuzugreifen, gleich, ob diese in einer Cloud, Unternehmensrechenzentren oder am Edge vorliegen. Das erfordert laut Deenik Speichersysteme und eine Systemsoftware, dies es ermöglicht, die Datenverwaltung zu vereinfachen und Silos aufzubrechen.
Glossar
Von Data Mesh bis Data Intelligence
Die wichtigsten Technologien, Architekturen und Vorgehensweisen im Bereich Data sind:
Data Mesh: Domaingesteuerte, analytische Datenarchitektur, in der Daten als Produkt behandelt werden. In dieser dezentralisierten Architektur werden Daten einzelner Business Units, also Domains, nicht in einer großen Plattform zusammengefügt, sondern von den zugehörigen Business Units betreut, aufbereitet und gespeichert.
Data Warehouse: Zentrale Datenbank für gefilterte, strukturierte Daten, die für bestimmte Anwendungsfälle vorgesehen sind. Im Vergleich zu Data Lakes sollen sie einen höheren Strukturierungsgrad aufweisen.
Data Lake: Ein Data Lake ist ein zentrales Auffangbecken für unbearbeitete Daten aller Art, auch für unstrukturierte Informationsbestände. Ein Nachteil ist, dass viele Data Lakes große Speicherkapazitäten erfordern, Stichwort Storage-Kosten. Hinzu kommt das Risiko, dass sich Data Lakes in „Datensümpfe“ (Data Swamps) verwandeln.
Data Fabric: Eine Data Fabric zielt darauf auf ab, eine einzelne, virtuelle Schicht für die Verwaltung verteilter Daten einzurichten. Eine Data Fabric ist technologiezentriert, während sich ein Data Mesh auf organisatorische Prozesse konzentriert. Dem Beratungsunternehmen BARC zufolge zeichnet sich eine Data Fabric durch zwei weitere Eigenschaften aus: die Verbindung von verteilten Plattformen, Anwendungen, Daten und Nutzergruppen sowie Funktionen, welche die Anwender entlasten, etwa das Optimieren von Prozessen durch KI-basierte Analysen, ein automatisiertes Monitoring und Management sowie Sicherheits- und Governance-Maßnahmen.
Data Intelligence: Das Erfassen, Extrahieren und Verknüpfen von Metadaten sowie deren Analyse, etwa mittels maschinellem Lernen. Dies können Data-Intelligence-Plattformen übernehmen, die wiederum Teil einer Datenplattform sind.









Be the first to comment