
Machine-Learning-Erfolgsberichte täuschen oft darüber hinweg, dass erhebliche Vorarbeit nötig ist, um dahin zu kommen. Lesen Sie, wie das - aus Sicht der Produktion - in der Praxis geht. [...]

Die beiden wichtigsten Stellhebel zur Steigerung der Produktivität in der diskreten Fertigung sind Qualitätsverbesserung, also die Reduzierung von Nacharbeitsaufwand und Ausschuss, und die Minimierung der Maschinenstillstandszeiten, die sich meist durch ungeplante Instandhaltungsmaßnahmen ergeben. Hier liefert Machine Learning (ML) in Form von Predictive Quality und Predictive Maintenance Lösungsansätze, die für die Produktion von hoher wirtschaftlicher Relevanz sind.
Darüber hinaus existieren weitere Ansätze, um mittels ML die Produktivität in der Produktion zu erhöhen, wie durch die Verkürzung von Rüstzeiten, intelligentes Programmieren von Robotern oder durch die Überwachung einzelner Fertigungsschritte mit Kameras. Unabhängig von der konkreten Problemstellung gilt beim Einsatz von ML grundsätzlich: Nicht das technisch Machbare, sondern das wirtschaftlich Sinnvolle sollte im Fokus stehen.
Machine Learning: Der Business Case entscheidet
Für einen entsprechenden Business Case gibt es vielfältige Ausgangspunkte. Dabei kann es sich um konkrete Problemstellungen aus den jeweiligen Fachbereichen, strategische Überlegungen in Form von Schwachstellenanalysen oder eine klare Roadmap für die Digitalisierung in der Produktion handeln, etwa durch Ableitung der jeweiligen Business Capabilities in einem Reifegradmodell. Ungeachtet des Grundes muss das wirtschaftliche Potenzial für die einzelnen Projekte oder Programme aufgezeigt werden. Hierüber lassen sich sehr stringent die Ziele und das Projektbudget ableiten.
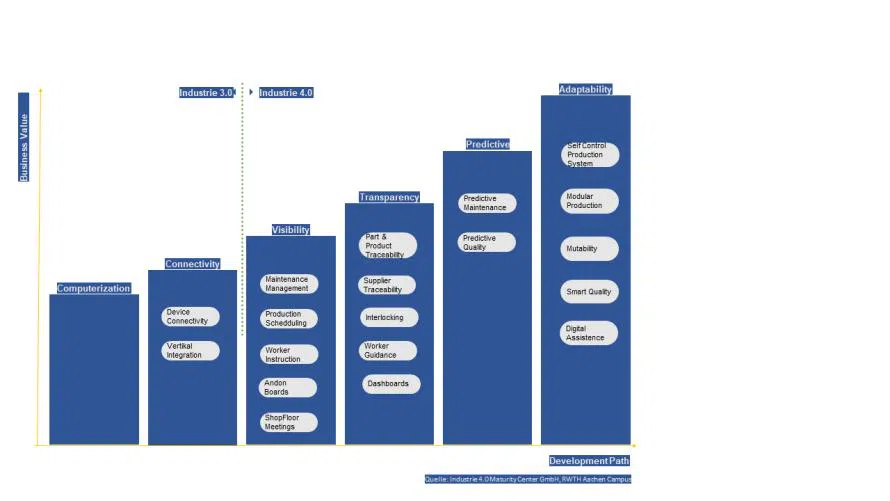
In der Praxis fällt vielfach auf, dass es bei derartigen, oftmals auch sehr ambitionierten Vorhaben an entsprechenden Vorarbeiten fehlt. So macht es wenig Sinn, sich über Predictive Maintenance Gedanken zu machen, wenn etwa das Stammdatenmanagement im Instandhaltungsbereich stark verbesserungsfähig ist oder Routineprozesse nicht automatisiert sind.
Maschinelles Lernen: Der Weg zu guten Daten
Bei der Ermittlung der wirtschaftlichen Potenziale helfen entsprechende Produktions-Dashboards mit etablierten Kennzahlen. Das aktive Arbeiten mit Kennzahlen wird durch derartige Dashboards geprägt, und sie unterstützen in der täglichen Arbeit. Der Automobilzulieferer Webasto beispielsweise hat ein sogenanntes Operations Performance Dashboard aufgesetzt. Hierbei handelt es sich um einen pyramidalen KPI-Ansatz auf Basis von maschinell erzeugten MES-Daten und manuellen Eingaben zur globalen Darstellung von Kennzahlen.
Die maschinelle Datenerzeugung ist nicht neu. Mit Einführung eines MES sollte dies erledigt sein – zumindest theoretisch. In der betrieblichen Praxis liegt der Fokus jedoch in der Regel vorrangig auf der Produktionssteuerung, also auf Fertigungsaufträgen und deren Rückmeldung zum Status inklusive der Speicherung von Traceability-Daten.
Bei der zunehmenden Digitalisierung kommen meist zusätzliche Anforderungen ins Spiel: Papierlose Fertigung, digitaler Performance Twin und selbstbeschreibende Maschinen sind in diesem Kontext wichtige Begriffe. Die für alle drei Punkte nötige Anbindung von Maschinen und Anlagen ist zeit- und kostenaufwändig und wird daher bei MES-Implementierungen oftmals auf die „lange Bank“ geschoben. Dieses Thema gilt es frühzeitig anzugehen. Denn eine hohe Datenqualität ist die Grundvoraussetzung für ML.
Keine ML-Zukunftsmusik: Selbstbeschreibende Maschinen
Ein Lösungsansatz für die Maschinenanbindung stellen selbstbeschreibende Maschinen dar. Sie sind im Kontext einer hohen Datenqualität somit von zentraler Bedeutung und klingen auf den ersten Blick nach „Zukunftsmusik“. Eine nähere Betrachtung zeigt, dass dem nicht so ist. Die Selbstbeschreibung umfasst:
- allgemeine Daten;
- Prozessdaten;
- Maschinendaten und Zustände.
Bei den allgemeinen Daten handelt es sich um Informationen zum Equipment (Hersteller, Typ, Technologie usw.). Die Prozessdaten bieten Details zu den einzelnen Fertigungsschritten, also wann ist ein Fertigungsschritt IO (In Ordnung) oder NIO (Nicht in Ordnung). Verbindende Fertigungsschritte, wie etwa ein Schraubvorgang, sind kritisch – im Sinne der Qualität. Somit gilt es hier, besonders Sorgfalt walten zu lassen. Derartige Fertigungsschritte müssen gezielt zu überwacht und gegebenenfalls über Prozessverriegelungen abgesichert werden.
Die Maschinendaten bilden unter anderem den jeweiligen Zustand der Anlagen ab – natürlich am besten in Echtzeit. Die IT-technische Anbindung erfolgt dann über etablierte Industrie-Standards wie OPC-UA oder mittels eines JSON-Strings. Im Prinzip muss ein Data Dictionary („Datenbibel“) für Maschinen und Anlagen erstellt werden. Soweit die Theorie, es gibt allerdings einen Haken: Vielfach erhalten wir Maschinendaten ausschließlich bei der Neubeschaffung von Maschinen und Anlagen.
Trotz des Bekenntnisses vieler Maschinen- und Anlagenbauer, Industrie-4.0-Standards wie OPC-UA zu unterstützen, tun sich in der betrieblichen Praxis Lücken auf. Die Erfahrung zeigt, dass Hersteller die jeweiligen Standards wie OPC-UA nur teilweise erfüllen oder den Standard individuell interpretieren. Einige Anbieter von Maschinen und Anlagen versuchen auf diese Weise auch neue Geschäftsmodelle zu etablieren. Eine mögliche Lösung ist, neben den Maschinen beim jeweiligen Hersteller zusätzlich digitale Assets zu kaufen. Hier könnten neben den Daten beispielsweise digitale Funktionalitäten wie Online-Monitoring oder gar Predictive Maintenance sinnvoll sein.
Da ein Industrieunternehmen in der Regel Maschinen und Anlagen mehrerer Hersteller im Einsatz hat, führt ein solcher Ansatz allerdings zu einem Nebeneinander von Insellösungen. Die Integration der einzelnen Lösungen in ein für den Anwender beherrschbares Gesamtsystem verursacht einen erheblichen Aufwand auf der IT-Seite im Unternehmen.
Bei Altanlagen gestaltet sich die Realisierung der Selbstbeschreibung und der Maschinenintegration deutlich schwieriger. Sogenannte Retrofit-Ansätze können hier gegebenenfalls Abhilfe schaffen. Es existieren entsprechende Lösungen am Markt – auch von deutschen Startups. Auch hier ist ein sorgfältige Prüfung des tatsächlichen Leistungsspektrums der infrage kommenden Anbieter zu empfehlen. Die Lösung sollte für möglichst viele Maschinen- und Anlagentypen und -Hersteller geeignet sein. Ziel sollte sein, einen digitalen Schatten oder einen digitalen Performance Twin für jedes produzierte Teil erstellen zu können.
Darüber hinaus gilt es zu klären, wem die Daten gehören, die während einer Fertigung erzeugt werden (Stichwort: Data Ownership). Der pragmatischste Weg besteht darin, dies in den Einkaufsbedingungen eines Unternehmens zentral festzuschreiben. Hierzu gibt es unter anderem vom VDA entsprechende Vorschläge. Ob sich das gegenüber Herstellern von Maschinen- und Anlagen durchsetzen lässt, hängt vom Einkaufsvolumen des jeweiligen Unternehmens ab.
Machine Learning in der Produktion: Erste Ergebnisse
Die Vorarbeiten zum effektiven Einsatz von Machine Learning können durchaus ein paar Monate in Anspruch nehmen. Auf dieser Basis lassen sich dann erste Erfolge etwa in Form eines Performance Dashboards vorweisen. Hierbei sollte dem Senior Management auch die gegebenenfalls schlechte Datenqualität vor Augen geführt werden. Die Unterstützung seitens der Führungsebene ist bei der Datenbereinigung (Data Governance) hilfreich. Andernfalls können derartige Projekte leicht scheitern.
Mit einer konsequenten Nutzung von Dashboards lassen sich im Unternehmen Kosteneinsparungen im sechsstelligen Bereich erzielen. Der wirtschaftliche Mehrwert dieser Ansätze kann durch eine lernende Organisation weiter gesteigert werden. Dies geschieht etwa durch die globale Verfügbarkeit derartiger Dashboards. Hierüber lassen sich Vergleiche zwischen den einzelnen Werken ziehen (Benchmarking der Werke) und schnell lokale Best Practice identifizieren inklusive deren Auswirkungen auf Kennzahlen.
Die beschriebenen Dashboards lassen sich um ein Online-Monitoring in Echtzeit für die Werke erweitern. Diese unterstützen Werksleiter, Linienverantwortliche, Schichtführer und Instandhalter in ihrer täglichen Arbeit. Ergänzend können Standardberichte Handlungsbedarfe aufzeigen werden und helfen, Potenziale zu heben. Ein Online-Monitoring ist im Bereich der Instandhaltung sehr hilfreich, unabhängig von der gewählten Strategie (zeitorientierte oder verbrauchsorientierte Instandhaltung). Es lassen sich hierüber die Instandhaltungsdauer, Maschinenstillstände und Ersatzteil-Lagerbestände reduzieren.
Für Lösungen der bisher beschriebenen Problemstellungen durch einzelne Dashboards können Unternehmen meist auf bereits verfügbare und bewährte Technologien, etwa Data Warehouses, zurückgreifen. Es lohnt sich diese entwickelten Lösungen kontinuierlich weiterzuentwickeln um weitere Optimierungspotentiale zu heben. Trendanalysen und das bereits beschriebene Online-Monitoring von Maschinenzuständen sind nur einige Beispiele für eine Erweiterung, ebenso wie das Informieren von Anwendern, wenn Maschinen und Anlagen individuell definierte Schwellenwerten von bestimmten Kennzahlen überschreiten.
Somit nimmt die Anzahl der Datenquellen und die Menge der gesammelten Daten zu. Zudem verbessert sich die Datenqualität kontinuierlich. Das steigert den Nutzwert der Daten erheblich. Ferner werden die Datenquellen immer vielfältiger. Wichtig ist, dass Mitarbeiter im Unternehmen lernen, mit Daten zu arbeiten – Stichwort digitale Transformation.
Maschinelles Lernen: Data-Lake-Reinhaltung
Um das wachsende Volumen an meist heterogenen und semi-strukturierten Daten nutzbar zu machen, müssen diese zunächst effizient gespeichert werden, zum Beispiel in Big-Data-Systemen. Dazu sind vorab entsprechende Speicher- und Verarbeitungshierarchien zu definieren. Edge- und Cloud-Computing bieten hier gute Lösungsansätze. Unternehmen sollten sich gut überlegen, ob sie sich eine eigene Big-Data-Infrastruktur aufbauen, denn die Komplexität eines solchen Projekts ist groß. Außerdem besteht die Gefahr, dass der Fokus zu sehr auf technischen Aspekte und weniger auf fachliche und wirtschaftliche Potenziale gelegt wird. Auch hier existieren am Markt etablierte Lösung von verschiedensten Lösungsanbietern. Als Startpunkt können die Daten auch in klassischen Datenbanksystemen gespeichert werden. Die Strategie hängt hierbei stark von der Unterschiedlichkeit der zu speichernden Daten ab.
Bei aller Daten-Sammlerfreude sollte stets die sinnhafte Verwendung der gespeicherten Daten im Vordergrund stehen. Der entstehende Data Lake darf nicht „verschlammen“ und die immer größere Datenmenge muss für die Fachanwender beherrschbar bleiben. Dafür sind eine ausführliche Dokumentation der gespeicherten Daten mit entsprechenden Speicherintervallen und das Festlegen einer zentralen fachlichen und technischen Verantwortung unerlässlich. Das hier beschriebene praxisorientierte Vorgehen ist in Abbildung 2 grafisch dargestellt.
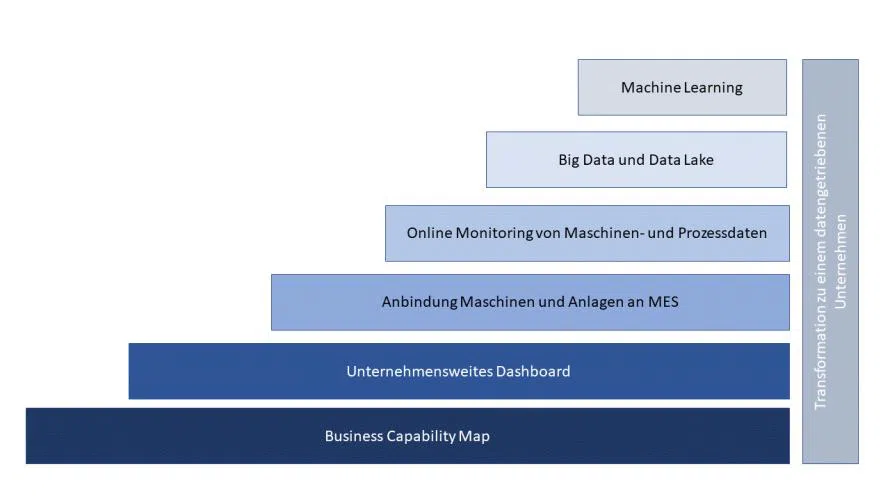
Die bisher beschriebenen klassischen Analyse-Ansätze werden zwangsläufig langfristig an ihre Grenzen kommen. ML stellt also die konsequente Weiterentwicklung dar. Bevor aber nun umfangreiche und damit auch kosten- und zeitintensive Projekte gestartet werden, sollte auf die Besonderheiten der Datenerhebung im Produktionsumfeld hingewiesen werden.
ML-Besonderheiten in der Produktion
Unabhängig von der spezifischen Problemstellung, geht es beim ML um das Finden und die Approximation einer Zielfunktion auf Basis entsprechender Daten. Die Zielfunktion ist in der Produktion allerdings bereits vorhanden. Produkte sind IO oder NIO. Somit ist nicht überwachtes Lernen sicherlich erstmal nicht die erste Wahl, da es hier ja genau um das selbständige Auffinden dieser Zielfunktion geht. Man würde ansonsten Gefahr laufen, in Richtung einer undefinierten Zielfunktion zu optimieren.
ML-Ansätze funktionieren gut bei großen und gleichverteilten Datenmengen – in unserem Fall idealerweise gleich viele NIO- und IO-Fälle. Genau diese Voraussetzung ist im Bereich Produktion nicht erfüllt. Es liegen normaler Weise sehr viele IO-Daten und sehr wenige NIO-Daten vor, da hauptsächlich „Gut-Teile“ produziert werden. Gleiches gilt für die Instandhaltung. Ungeachtet des konkreten Verhältnisses sind die verfügbaren Daten und deren Verteilung für ML-Ansätze somit nicht günstig. Dazu kommt, dass die Anzahl der vorhandenen Daten im Vergleich zu anderen Domänen gering ist, da beispielsweise in der Automobilindustrie im Model-Mix produziert wird. Normierungsansätze über mehrere Produkte oder Produktvarianten können hier gegebenenfalls Abhilfe schaffen. Aber vielfach sind die Daten auch nicht vollständig, z. B. durch fehlende manuelle Eingaben. Somit reduziert sich die nutzbare Datenbasis noch weiter.
Ein weiterer Punkt ist die Bestimmung, wann ein mathematisches Modell praxistauglich ist. Hier gilt es zwischen Genauigkeit und Präzision zu differenzieren. Vielfach wird bei der Güte von Algorithmen mit deren Genauigkeitsmaß argumentiert. Um den Unterschied zwischen beiden Definitionen zu verdeutlichen, soll ein kurzes Beispiel helfen: 100.000 Teile werden produziert, 99.000 sind davon IO und 1.000 NIO.
Bei einer Genauigkeit von 99 Prozent könnte das mathematische Modell genau die 99.000 IO-Teile erkennen. Auf den ersten Blick klingt der Genauigkeitswert von 99 Prozent damit sehr gut. Für die Produktion wäre dieses Modell aber wertlos, da er genausogut die 1.000 NIO-Teile nicht erkennen könnte. Das oberste Ziel eines Industrieunternehmens ist es aber, ausschließlich IO-Produkte herzustellen und den Kunden mit qualitativ hochwertigen und fehlerfreien Produkten zu versorgen.
Qualitätskontrollen während der Produktion und umfangreiche End-of-Line-Prüfungen haben einen entsprechend hohen Stellenwert. Hier kommt nun die Präzision ins Spiel: Der Fokus liegt hierbei ausschließlich auf dem Erkennen der NIO-Teile. Es sollten unnötige Nacharbeiten vermieden werden. In unserem obigen Beispiel wäre die Präzision des Ansatzes bei 0 Prozent und das mathematische Modell damit für die praktische Anwendung unbrauchbar.
ML-Projekte: Nicht ohne Vorarbeit
Die im letzten Absatz aufgeführten Herausforderungen machen die Arbeit nicht unbedingt einfacher. Für die vorausschauende Instandhaltung (Predictive Maintenance) bieten sich als gute Alternativen zu Eigenentwicklungen Lösungen der jeweiligen Maschinenhersteller an, soweit es sich nicht um Sondermaschinenhersteller handelt. Auch für das Online-Monitoring bieten Maschinen- und Anlagenbauer entsprechende Lösungen an.
Beim Thema Smart Quality dagegen bleibt in der Regel nur die Eigenentwicklung. Unabhängig vom gewählten Ansatz sollte allerdings vermieden werden, Algorithmen und Modelle vollständig neu zu entwickeln. Die Programmiersprache Python beispielsweise stellt ein breites Spektrum an mathematischen Modellen in Form entsprechender Bibliotheken zur Verfügung. Die Auswahl und die Anpassung dieser Modelle auf die eigene Problemstellung ist bereits recht anspruchsvoll und sollte nicht weiter verkompliziert werden. Alle Cloud-Anbieter haben entsprechende Lösungsbausteine in ihrem Portfolio.
Der Weg hin zu ML ist vielfach langwierig, da umfangreiche Vorarbeiten erforderlich sind. Erst wenn diese getätigt wurden, haben entsprechende Projekte auch Erfolgsaussichten. Werden diese Vorarbeiten nicht getätigt, so droht Frust in den Fachabteilungen und der Verlust an Investitionen bis hin zur Abkehr von diesen durchaus zielführenden Ansätzen.
Wichtig ist hierbei eine klare Strategie mit entsprechenden Zielen zu definieren. Diese gilt es mit konkreten Projekten zu unterlegt. Somit kann Schritt für Schritt vorangegangen und das Know-how im eigenen Unternehmen sukzessive aufgebaut werden. Auf Basis der selbst gemachten Erfahrungen und Ergebnisse kann die Strategie entsprechend angepasst werden.
*In seinen beruflichen Stationen bei Siemens, Staufen AG, MT Aerospace und aktuell Webasto trug Dr. Walter Huber überwiegend die Verantwortung für strategische Veränderungen. Aktuell ist er bei Webasto als Director im Produktionsbereich/Manufacturing Engineering beschäftigt. Im Laufe seiner beruflichen Tätigkeit hat er über 30 Industrie 4.0 Projekte umgesetzt und mehrere Firmen in Richtung Industrie 4.0 transformiert. Hierzu ist auch beim Springer Verlag das Buch mit dem Titel Industrie 4.0 in der Automobilproduktion erschienen. Ein weiteres Buch mit dem Titel Wie Technologien unsere Wirtschaft und unsere Unternehmen verändert erscheint ebenfalls beim Springer Verlag.









Be the first to comment