
In vielen kleinen und mittelständischen Unternehmen gehört SharePoint zu den kritischen Anwendungen, die auf keinen Fall ausfallen dürfen. Dieser Ratgeber beschreibt, wie sich eine hochverfügbare SharePoint-Umgebung kostengünstig mit Hilfe von Virtualisierungstechniken einrichten lässt. [...]
SCHRITT FÜR SCHRITT ZUR HOCHVERFÜGBAREN INFRASTRUKTUR
Schritt 1: Arbeits- und Plattenspeicher reservieren
Wichtig ist, für ausreichend Arbeitsspeicher der virtuellen Maschinen (VM) zu sorgen, damit sich die virtualisierte Umgebung nicht negativ auf die Performance auswirkt. Im Normalfall weist der Host die Ressourcen – auch die CPU-Leistung – dynamisch zu, wobei die VM jedoch unbedingt über eine gewisse Grundperformance verfügen sollte. Als Richtwert dient ein Drittel der Zielleistung.
Zwar können Festplatten auf virtuellen SharePoint-Servern dynamisch wachsen. Zu beachten ist dabei aber, dass der IT-Administrator die virtuellen Festplatten des SQL-Servers in ihrer vollständigen Größe anlegt. Zudem sollte er die Datenbanken manuell mit einer Anfangsgröße festlegen, die sich am erwarteten Datenvolumen orientiert. Für eine Farm mit hohem Upload-Anteil sind die Standardeinstellungen nicht zu empfehlen.
Schritt 2: Umsetzung der Infrastruktur: Virtuelle Maschinen
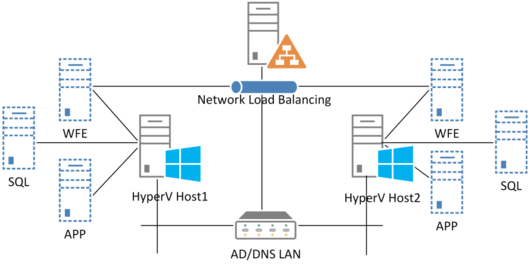
Verteilung der virtuellen Maschinen auf die Hosts.
Foto: Comparex
Nun verteilt der IT-Administrator die VMs auf die entsprechenden Hosts. Dadurch ist das Gesamtsystem nicht mehr von einzelnen Komponenten abhängig. Dementsprechend könnten der Hyper-V-Host 1 und der Hyper-V-Host 2 zum Beispiel jeweils über einen SharePoint-Web-Frontend-Server, einen SharePoint-Anwendungsserver und einen SQL-Server verfügen.
So lässt sich mit einem einzelnen Host die gesamte Serverfarm komplett bereitstellen. Dabei müssen die Dimensionen der VMs so ausgelegt sein, dass sie die Leistungsanforderungen aus den Service Level Agreements (SLA) zu 100 Prozent erfüllen.
Schritt 3: Umsetzung der Infrastruktur: Netzwerk
Der Hyper-V-Host muss jede Netzwerkverbindung der VM redundant abbilden. Tabelle 2 zeigt, dass für jedes Fachbereichsteam eines der Teammitglieder auf einen zugeordneten Port eines Switches verbunden wird. So ist das Team selbst dann erreichbar, wenn ein Switch ausfällt.

Tabelle 1: Netzanbindung – Teaming der Netzwerk-Adapter des Hyper-V-Hosts
Das Netz selbst wird in vier Bereiche aufgeteilt, wobei die IP-Adressen in Abbildung 3 exemplarisch sind:
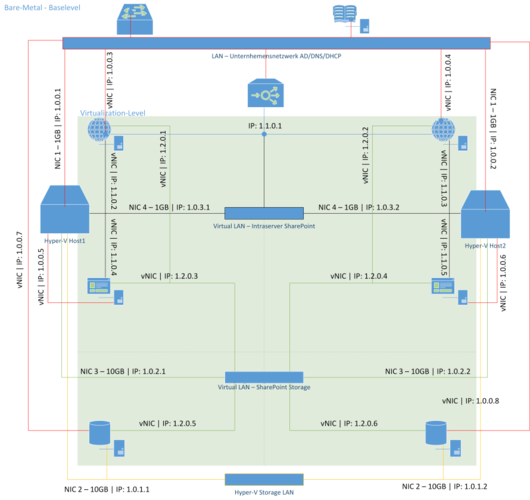
Bildtext Die Netzaufteilung.
Foto: Comparex
Der rote Bereich besteht aus der Kommunikation mit dem LAN sowie den Application Delivery Controllern und DNS-Servern. Mit Hilfe von zwei 1-GBit-Netzwerkkarten wird das Netz in einem Teaming-Verbund des Hostsystems angelegt. Die Einbindung erfolgt über einen virtuellen Switch auf jedem Host, der die Kommunikation der VM mit der Netzwerkinfrastruktur ermöglicht.
Im schwarzen Bereich wird die Kommunikation der SharePoint-Server untereinander geregelt. So sind zwei weitere 1-GBit/s-Netzwerkkarten in einem Teaming-Verbund des Hosts an die virtuellen Switches angekoppelt. Zudem findet hier das Load-Balancing zwischen den Web-Frontend (WFE)-Servern statt.
Der grüne Bereich ermöglicht die Kommunikation der SQL-Server mit den SharePoint-Servern. Hier erfolgt die Anbindung an die Hyper-V-Hosts über zwei 1-GBit/s-LAN-Adapter in einem Teaming-Verbund.
Im gelben Bereich schließlich findet die Kommunikation der SQL-Server untereinander statt. Die zweiten 10-GBit/s-Adapter sind als Pass-Through-Karten in die virtuellen Server integriert; das Clustering erfolgt in Form einer Hochverfügbarkeitsgruppe direkt über dieses Netz.
Schritt 4: Umsetzung der Infrastruktur: Anwendung
Die Tabellen 3 und 4 zeigen exemplarisch, wie die Verteilung der Anwendungen aussehen müsste, damit sie bei einem Systemausfall weiterhin zur Verfügung stehen. Dafür sind alle Komponenten und Rollen der SharePoint-Suche auf beiden Servern bereitzustellen.

Tabelle 2: Verteilung der Services (Quelle Comparex)
Darüber hinaus muss die Verteilung der Dienstanwendungen ebenfalls geplant werden. Sie könnte sich wie folgt gestalten – nur verwendete Dienste:

Tabelle 3: Verteilung der Dienstanwendungen (Quelle Comparex)
Wie bereits erwähnt, kommt bei der Suche hinzu, dass sämtliche Komponenten und Rollen dieser speziellen Dienstanwendung auf beiden Servern bereitzustellen sind.
Schritt 5: Umsetzung Infrastruktur: Datenbank
Grundlage für Redundanz und Hochverfügbarkeit der SQL-Datenbank auf Basis von SQL Server 2012 sind die Hochverfügbarkeitsgruppen. Hierzu benötigt das Unternehmen mindestens zwei Windows-Server in einem Windows-Server-Failover-Cluster. Bei Hochverfügbarkeitsgruppen spricht man dann von primären und sekundären Replikas. Es lassen sich bis zu fünf Knoten implementieren: eine primäre Replika und bis zu vier sekundäre.
Diese Strategie hat einige Vorteile:
- Sie erfordert keinen zentralen Speicher.
- Eine sekundäre Replika kann als „lesbar“ konfiguriert werden. Das ermöglicht zum Beispiel die Umleitung der Suche auf diese Datenbank.
- Der Failover erfolgt automatisch.
- Pro Gruppe lassen sich unterschiedliche Synchronisierungsmechanismen einsetzen.
- Es können jederzeit neue Datenbanken in die Gruppe aufgenommen werden.
- Die Fehlertoleranz ist relativ hoch. Wenn zum Beispiel durch eine „still defekte“ Festplatte die Datendateien der Datenbank korrupt sind, findet sich dieser Fehler nicht in den anderen Replikas.
Generell werden die Daten auf Basis von SQL-Transaktionen zwischen den Replikas synchronisiert. Dies kann über synchrone oder asynchrone Commits erfolgen. Beim synchronen Commit werden alle Transaktionen auf allen Replikas synchron durchgeführt. Das heißt, wenn ein Nutzer eine Änderung vornimmt, wird diese in einer Transaktion aufgereiht. Um eine Transaktion konsistent in die Datenbank zu schreiben, braucht es ein Commit, quasi eine Bestätigung, um die Transaktion erfolgreich auszuführen.
Bei synchronen Commits wartet die primäre Replika, also der Server, auf dem der Nutzer arbeitet, bis die Transaktionen auf allen sekundären Replikas erfolgreich ausgeführt wurden. Änderungen erfolgen daher langsamer. Der Vorteil ist, dass alle Replikas synchron sind und im Fehlerfall kaum Daten verloren gehen. Diese Option bietet sich für Datenbanken mit geringen Änderungsfrequenzen an.
Beim asynchronen Commit übernimmt die primäre Replika die Änderung direkt, unabhängig davon, ob die sekundären Replikas das bereits getan haben. Aus Sicht des Nutzers werden Änderungen umgehend vorgenommen. Bei Ausfall einer Replika können jedoch Daten verloren gehen. Der asynchrone Commit eignet sich daher für Datenbanken mit häufigen Änderungen.









Be the first to comment