
Machine-Learning-Algorithmen machen Predictive-Maintenance-Modelle erst möglich. So können auch Sie lernfähige Modelle für solche Anwendungen entwickeln. [...]

Die vorausschauende Wartung, neudeutsch Predictive Maintenance genannt, lebt von Daten und einem hohen Grad an Automatisierung. Im Kern geht es darum, den Zustand von Maschinen kontinuierlich zu überwachen und darauf aufbauend Betrieb und Wartungsintensität zu optimieren. Damit das gelingt, müssen die gesammelten Messdaten automatisch interpretiert werden.
Entscheidend dafür sind Machine-Learning-Algorithmen. Mithilfe dieser mathematischen Methoden lassen sich aus Daten funktionale Zusammenhänge ableiten. Dabei geht es darum, die Zusammenhänge zu finden, die am besten die jeweiligen Anforderungen abdecken und helfen, die angestrebten Ziele zu erreichen: eine Zustandsdiagnose des überwachten Systems und eine möglichst verlässliche Vorhersage seiner nutzbaren Restlebensdauer, der Prognose des sogenannten Remaining Useful Life (RUL).
Diese Algorithmen machen die Modelle lernfähig. Damit automatisieren sie nicht nur die vorausschauende Wartung, sie sorgen auch für eine adäquate Reaktion bei Veränderungen im Verhalten der Maschinen, aber auch in den Rahmenbedingungen. Sie schaffen so die Voraussetzung dafür, dass sich Wartungsvorgänge, -intervalle und Ersatzteilhaltung optimal an die jeweils aktuellen Bedingungen anpassen lassen. Und sie helfen dabei, Abweichungen zu erkennen, ehe die jeweilige Maschine größeren Schaden nimmt oder beispielsweise eine Flugzeugturbine nicht mehr voll funktionsfähig ist.
Im Folgenden wird schrittweise dargestellt, wie Unternehmen vorgehen sollten, wenn sie ein Predictive-Maintenance-Projekt unter Einsatz von Machine Learning umsetzen wollen. Erste Voraussetzung für ein Predictive-Maintenance-Projekt ist die Bestückung der Maschinen mit Sensoren und ihre Vernetzung. Idealerweise ist diese Voraussetzung schon lange vor Projektstart gegeben, denn je mehr Daten – auch aus der Vergangenheit – zur Verfügung stehen, desto treffsicherer sind die Ergebnisse.
Der Predictive-Maintenance-Start: Überblick verschaffen
Der erste Schritt zur Entwicklung passender Algorithmen ist die Daten-Inventur. Denn nur wenn das Projektteam weiß, welche Maschinendaten überhaupt verfügbar sind, kann es die nächsten Schritte zielgerichtet angehen. Relevante Daten können beispielsweise sein:
- Zustands-/Messdaten der Maschine (häufig Zeitreihen, wie die Temperatur zum Zeitpunkt X, Y, Z);
- unstrukturierte Daten (beispielsweise Bilder oder Audiosignale);
- statische Eigenschaften (etwa Firmwareversion, Herstellungsdatum oder Aufstellungsort der Maschine).
Relevant für die Verwertbarkeit der Daten ist, wie sie gesammelt werden und wie vollständig sie sind: Liegen bestimmte Daten nur Event-getriggert vor oder sind sie in konstanten Messreihen verfügbar – und wenn ja, in welcher Frequenz werden sie gesammelt? Sind die Messreihen lückenlos dokumentiert?
Generell ist die Datenaufbereitung entscheidend für den Erfolg eines Projekts. Häufig unterschätzen Unternehmen, wie viel Zeit sie dafür aufwenden müssen, um die Datensätze zu reinigen, falsche Werte zu löschen, fehlende Werte aufzufüllen und zu verstehen, wie und unter welchen Umständen die Daten gemessen wurden.
Servicedaten für Machine Learning nutzen
Besonderes Augenmerk verdienen eventuell vorhandene Service- und Reparaturdaten, sie sind ein wahrer Wissensschatz und die Basis für eine RUL-Prognose. Wichtige Angaben sind zum Beispiel: Welche Maschine ist wann ausgefallen? Was war defekt und was wurde repariert? Das Projektteam muss dabei vor allem prüfen, ob sich die Servicedaten mit den Zustandsdaten „matchen“ lassen. Denn anhand der Reparaturhistorie lassen sich die Zustände vor und nach der Reparatur abgleichen. Auf dieser Basis kann das System lernen, was „kaputt“ im Einzelfall überhaupt bedeutet.
Sind Servicedaten verfügbar, folgt zunächst deren Priorisierung: Welche Maschinentypen sind am häufigsten defekt? Welche Bauteile fallen am ehesten aus oder sind am teuersten zu reparieren? Im Anschluss muss das Unternehmen dann herausfinden, welche Messwerte – zum Beispiel physikalische Messgrößen – für das Versagen eines Bauteils oder einer Maschine relevant sein könnten. Dies ist die Voraussetzung, um die verfügbaren Daten im Hinblick auf die Modellbildung zu sichten und zu bewerten: Was könnte relevant sein, was wird überhaupt gemessen? In dieser Phase ist es sinnvoll, Experten zu Rate zu ziehen, die sich mit den Maschinen auskennen.
Steht der Überblick über die vorhandenen Daten und deren grundsätzliche Relevanz, sollte das Projektteam klären, welche Fragestellungen sich im Zusammenhang mit den angestrebten Projektzielen überhaupt beantworten lassen. Vor allem die finanzielle Perspektive ist wichtig. Am interessantesten sind Anwendungsfälle, bei denen viel Geld im Spiel ist: besonders teure Maschinen oder solche, die besonders häufig ausfallen oder durch Ausfälle besonders hohe Kosten verursachen. Diese Fälle sollten höchste Priorität genießen.
Spätestens jetzt wird deutlich: Ein solches Projekt ist komplex, und es sind viele Personen mit den unterschiedlichsten Sichtweisen und Kompetenzen eingebunden. Deshalb empfiehlt es sich für Unternehmen, schon früh einen Data Scientist einzubinden. Er ist der Kommunikator, der die Fäden in der Hand hält, der mit Datensammlern, Entwicklern, Servicetechnikern und anderen Experten redet, deren Informationen aufbereitet und in das Projekt eingliedert.
Entwicklung der Machine-Learning-„Intelligenz“
Doch wie erstellt man jetzt technisch den „intelligenten“ Algorithmus? Vorab: Berührungsängste sind nicht angebracht. Es gibt mittlerweile eine Reihe an guten Tools, die sich an unterschiedliche Zielgruppen richten:
- Von IoT-Herstellern bereits integrierte Algorithmen oder vorgefertigte Services wie Azure Cognitive Services oder Amazon AWS AI Services bieten eine gute Grundlage für den schnellen Einstieg. Diese Tools sind allerdings eine „Black Box“ und nur in relativ geringem Umfang anpassbar.
- Öffentlich verfügbare KI-Programmierbibliotheken oder Algorithmen-Baukästen eignen sich für eine schnelle Modellentwicklung und greifen häufig unter anderem auf die interpretierte Sprache Python zurück. Hier gibt es zum Beispiel die Bibliothek Keras für neuronale Netzwerke oder scikit-learn für „klassische“ Machine-Learning-Modelle. Sie nutzen vordefinierte Berechnungsmethoden, bieten aber bereits mehr Eingriffsmöglichkeiten.
- Noch eine Ebene tiefer gehen beispielsweise Open-Source-Programmbibliotheken wie PyTorch und TensorFlow. Sie unterstützen die komplette Eigenentwicklung von Algorithmen und besitzen auch eine Python-Anbindung.
Predictive Maintenance am Beispiel einer Flugzeugturbine
Nachfolgend ein einfaches Beispiel für einen Entwicklungsprozess mit einem Algorithmen-Baukasten. Als Datengrundlage dient der Datensatz „Turbofan Engine Degradation Simulation Data Set“ aus dem Nasa Prognostics Data Repository. In diesem Datensatz wird der Betrieb von Flugzeugturbinen simuliert, deren – ebenfalls simulierte – Sensormesswerte für viele Flüge verfügbar sind. Das Szenario: Der Turbinenzustand verschlechtert sich nach und nach. Ziel ist die Vorhersage, wann die Turbine voraussichtlich nicht mehr funktionsfähig sein wird.
Voraussetzung hierfür sind Service- und Reparaturdaten, mit denen sich die korrekte Antwort für die aufgezeichneten Daten berechnen lässt. Diese Antwort gilt es herauszufiltern und zu verifizieren.
Als Technologien dienen die Programmiersprache Python – einfach lesbar für den einigermaßen versierten ITler, selbst wenn er kein Python kann – und scikit-learn zur Nutzung der „intelligenten“ Algorithmen. Zum selbst ausprobieren: Code downloaden oder unter Windows Anaconda installieren und mit Jupyter Notebook arbeiten. Nach der Installation von Anaconda kann aus dem Anaconda Navigator direkt ein Notebook aufgerufen werden.
Es gibt unterschiedliche Möglichkeiten, die Problemstellung zu definieren, die zur Prognose führt:
- Regression, also der Versuch, die verbleibende Lebenszeit der Turbine in Tagen vorherzusagen. Hier ist die Vorhersage ein Zahlenwert.
- Klassifikation. Sie arbeitet mit klar definierten Annahmen, wobei die sogenannte Binärklassifikation nur einen Wert zugrunde legt. Zum Beispiel: Das Remaining Useful Life (RUL) der Turbine beträgt zehn Tage. Hier ist die Antwort eine Bestätigung der Annahme (ja) oder deren Verneinung (nein). Möglich ist auch eine Multiklassifikation, also die Annahme eines RUL von 10, 15, 20, 30, … Tagen. Die Antwort ist jeweils ja oder nein.
ML-Algorithmen: Mathematischer Zusammenhang
Betrachten wir der Einfachheit halber die Binärklassifikation. Zunächst gilt es einen mathematischen Zusammenhang (Funktion) zwischen den Sensormesswerten und dem Vorhersageziel (RUL) zu finden. Die Art der Zusammenhänge – zum Beispiel linear, nicht-linear – bedingt den Algorithmus, mit dem sich der beste mathematische Zusammenhang finden lässt. Wir wählen hier die logistische Regression, sie ist ein für Binärklassifikation sehr einfacher Algorithmus.
Zur Erinnerung: Die Daten in unserem Idealbeispiel enthalten Sensormesswerte zu bestimmten Zeitpunkten und die vorberechnete, korrekte Antwort aus den Servicedaten. Für unser Beispiel teilen wir die Daten vereinfachend in zwei Teile auf: Die Trainingsdaten, um die Funktion anzupassen und die Testdaten, um ihre Qualität zu bewerten.
Dazu „füttern“ wir das Modell mit den Sensormesswerten aus den Trainingsdaten und vergleichen die Ausgabe unseres Modells (defekt – ja/nein) mit dem korrekten Wert, der in der Realität aus der Servicehistorie hervorgeht. Aus der realen Servicehistorie ist beispielsweise bekannt, wann genau die Turbine nicht mehr funktionstüchtig war. Werden diese Daten über die aufgezeichneten Messdaten gelegt, lässt sich die korrekte Antwort im Voraus berechnen.
Jetzt nimmt man einen Teil aus der Historie und die dazugehörigen korrekten Antworten, um das Modell zu erzeugen. Der andere Teil, die Testdaten, wird genutzt, um zu prüfen, wie gut das Modell jetzt ist: Die Sensorwerte dienen als Input, die Ergebnisse der Modellvorhersage werden wieder mit dem korrekten Wert verglichen.
Qualität des Machine-Learning-Modells prüfen
Anhand der Trainingsdaten wird die Funktion gesucht, die den Zusammenhang zwischen Sensormesswerten und RUL so gut wie möglich nachbildet. Um die Qualität des so trainierten Modells zu bewerten, geben wir die Testdaten nach demselben Muster ein. (Anmerkung: In der Realität ist die korrekte Aufteilung des Datensatzes etwas komplizierter.)
Der Datensatz in unserer Turbinen-Simulation ist schon gut aufbereitet. Deshalb ist hier je nach eingesetzter Machine-Learning-Methode etwas „Feature Engineering“ notwendig, wie etwa das Erzeugen neuer Spalten. Dies macht es dem Algorithmus leichter, eine gute Lösung zu finden. Für unser Testbeispiel lassen wir diesen Schritt der Einfachheit halber aus.
Für die Anpassung unseres Modells verwenden wir scikit-learn, eine einfache Schnittstelle, um viele Algorithmen zu nutzen. Sie bietet „Schablonen“ an, die lediglich mit Testdaten befüllt werden müssen. Das Prinzip: Schablone initialisieren, Daten einladen, Optimierungsparameter wählen, Optimierung starten und Ergebnis auslesen.
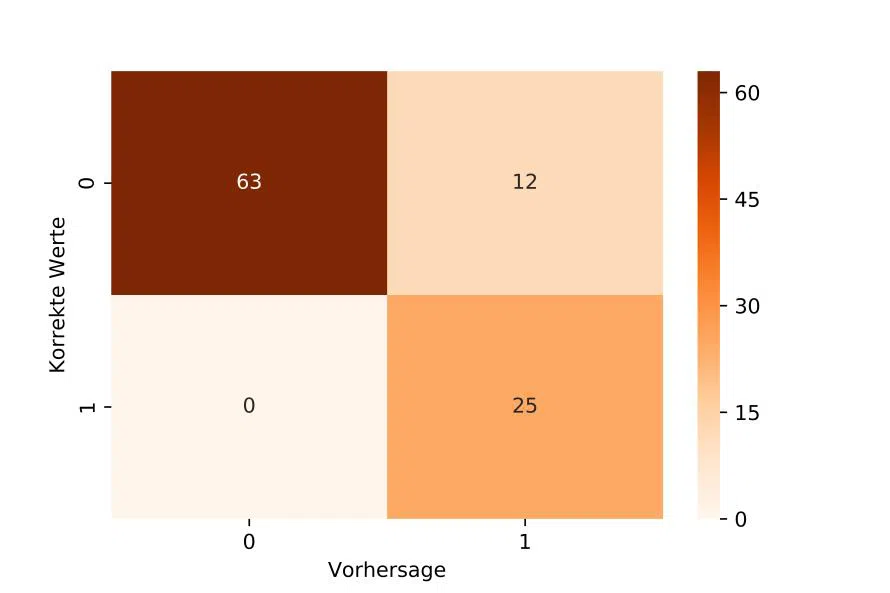
Ein Blick auf die Konfusionsmatrix zeigt zum Beispiel in der ersten Zeile, dass wir mit 63 korrekterweise eine Turbine als „wird in den nächsten 30 Zyklen nicht kaputt gehen“ klassifiziert haben, aber zwölf mal fälschlicherweise als „wird in den nächsten 30 Zyklen kaputt gehen“.
Vorhersagequalität ist immer relativ, da sie abhängig ist vom konkreten Einsatzszenario. Wichtig ist dabei vor allem: Welche Folgen eines falschen Ergebnisses sind akzeptabel und welche nicht? Beispiel: Das Modell initiiert die Wartung der Maschine, obwohl sie noch gar nicht erforderlich wäre (falsch-positives Ergebnis). Oder die Wartung erfolgt zu spät und die Maschine fällt aus (falsch-negatives Ergebnis). Bei einer Flugzeugturbine ist letzteres sicherlich nicht akzeptabel.
Fazit: Keine Angst vor Künstlicher Intelligenz
Unternehmen, die ihre Wertschöpfung mit vorausschauender Wartung steigern wollen, kommen nicht daran vorbei, sich mit Künstlicher Intelligenz auseinanderzusetzen. Denn ohne Machine Learning ist wirksame Predictive Maintenance nicht möglich. Der Einstieg in die Entwicklung von Machine-Learning-Algorithmen ist aber nicht so schwierig, wie es auf den ersten Blick erscheint.
Natürlich ist das Erreichen der Produktionsreife komplizierter, abhängig vom Anwendungsfall und vom Risiko im praktischen Einsatz. In aller Regel ist es daher sinnvoll, einen Spezialisten einzubinden, der über das erforderliche Knowhow verfügt und alle involvierten Parteien unter einen Hut bringt.
*Julian Mehne ist Data Scientist bei doubleSlash Net-Business GmbH.









Be the first to comment