
Das Volumen an personenbezogenen Daten explodiert förmlich. Nicht zuletzt ist das Angebot von personenbezogenen Daten durch die heutigen KI-unterstützen Tools enorm gestiegen. Fest steht, dass Anonymisierung dazu dienen kann, die Risiken für betroffene Personen zu minimieren. [...]
Praxisleitfaden
Die DSGVO-zt GmbH hat zur Anonymisierung einen Praxisleitfaden. Dieser kann um 75 Euro unter folgendem Link bestellt werden: Praxisleitfaden Anonymisierung.
- Anforderungen an die Anonymisierung
- Wann ist eine Anonymisierung hinreichend?
Wann eine Anonymisierung als ausreichend angesehen werden kann, lässt die DSGVO offen. Erwägungsgrund 26 Satz 3 und 4 enthält folgende Hinweise:
- „Um festzustellen, ob eine natürliche Person identifizierbar ist, sollten alle Mittel berücksichtigt werden, die von dem Verantwortlichen oder einer anderen Person nach allgemeinem Ermessen wahrscheinlich genutzt werden, um die natürliche Person direkt oder indirekt zu identifizieren, wie beispielsweise das Aussondern.
- Bei der Feststellung, ob Mittel nach allgemeinem Ermessen wahrscheinlich zur Identifizierung der natürlichen Person genutzt werden, sollten alle objektiven Faktoren, wie die
- Kosten der Identifizierung und
- der dafür erforderliche Zeitaufwand
herangezogen werden, wobei die zum Zeitpunkt der Verarbeitung verfügbare Technologie und technologische Entwicklungen zu berücksichtigen sind“.
- Abgrenzung zur Pseudonymisierung
Von anonymisierten Daten abzugrenzen sind insbesondere pseudonymisierte Daten. Darunter versteht die DSGVO „die Verarbeitung personenbezogener Daten in einer Weise, dass die personenbezogenen Daten ohne Hinzuziehung zusätzlicher Informationen nicht mehr einer spezifischen betroffenen Person zugeordnet werden. Die Ausführungen zur Pseudonymisierung lesen Sie im nächsten Tagebuch-Kapitel.
Während die Anonymisierung die Entfernung des Personenbezugs zum Ziel hat, bleibt im Rahmen der Pseudonymisierung eine Re-Identifizierung der betroffenen Personen möglich. Die für die Re-Identifikation erforderlichen Daten müssen jedoch gesondert aufbewahrt und durch technische/organisatorische Maßnahmen geschützt werden.
- Anonymisierung als Verarbeitung
- Allgemeines zur Anonymisierung
- Begriff der Verarbeitung
Art. 4 Nr. 2 DSGVO definiert den Begriff der Verarbeitung als „jeden mit oder ohne Hilfe automatisierter Verfahren ausgeführten Vorgang oder jede solche Vorgangsreihe im Zusammenhang mit personenbezogenen Daten“ und nennt einige nicht abschließende Regelbeispiele für Verarbeitungsvorgänge. Der Begriff wird weit verstanden und umfasst letztlich jeden Umgang mit personenbezogenen Daten.
- Anonymisierung als Verarbeitung
Bei der Anonymisierung handelt es sich um einen Vorgang, der darauf gerichtet ist, dass die personenbezogenen Daten ihren Personenbezug verlieren. Dies legt den Schluss nahe, dass die personenbezogenen Daten durch die Anonymisierung – in ihrer Personenbezogenheit – verändert werden (à Art. 4 Nr. 2 Abs. 7 DSGVO).
Die Anonymisierung stellt eine Verarbeitung dar und bedarf als solche einer Rechtsgrundlage.
- Re-Identifizierung
Wenn sich ursprünglich als anonym eingestufte Daten als personenbeziehbar erweisen, spricht man von einer Re-Identifizierung. Dies könnte aufgrund neu entwickelter technischer oder mathematischer Verfahren möglich sein.
In diesem Fall können die betreffenden Daten nicht mehr als anonym bezeichnet werden und es gelten alle Anforderungen des Datenschutzrechts wie z.B:
- Gewährleistung der Sicherheit der Verarbeitung
- Durchführung einer Datenschutz-Folgenabschätzung
- Gewährleistung der Rechte der Betroffenen
- Angabe der Rechtsgrundlage für die Verarbeitung
- Anonymisierung als Löschung
Soweit personenbezogene Daten einer frühzeitigen Löschung unterliegen, können diese anonymisiert werden (à Art. 6 Abs. 1 lit. c) DSGVO). Die Löschungspflicht von personenbezogenen Daten läßt sich auch durch die Anonymisierung erfüllen.
- Zunächst ist hinsichtlich der Fragestellung zwischen der Verpflichtung zur Speicherbegrenzung und dem Recht auf Löschung nach zu unterscheiden. Art. 5 Abs. 1 lit. e) DSGVO verlangt nicht ausdrücklich die Löschung von (personenbezogenen) Daten. Die Löschung der Daten ist nach der Systematik der DSGVO nur eine von mehreren Möglichkeiten, die Anforderungen des Art. 5 der DSGVO zu erfüllen. Eine Löschung ist nicht erforderlich, wenn der Personenbezug durch Anonymisierung wirksam beseitigt werden kann.
- Davon zu unterscheiden ist das Recht auf Löschung nach Art. 17. Danach hat der Verantwortliche personenbezogene Daten unverzüglich zu löschen, wenn sie für die Zwecke, für die sie erhoben oder auf sonstige Weise verarbeitet wurden, nicht mehr erforderlich sind. Art. 17 nimmt damit Bezug auf die festgelegten Grundsätze der Zweckbindung und der Datenminimierung. Der Grundsatz der Speicherbegrenzung kann daher Grundlage für einen Löschungsanspruch sein. Anonyme Informationen sind nach Erwägungsgrund 26 der DSGVO solche Informationen, die sich nicht auf eine bestimmte oder bestimmbare natürliche Person beziehen, oder personenbezogene Daten, die anonymisiert wurden. Für anonymisierte Daten gelten die Grundsätze des Datenschutzes nicht.
- Dass es sich bei Löschung und Vernichtung um zwei alternative Verarbeitungsvorgänge handelt, wird auch durch die Formulierung „Löschen oder Vernichten“ in Art. 4 deutlich. Diese Argumentation lässt sich auch auf den Löschungsanspruch übertragen. Aus Sicht der BfDI kann die Pflicht zur Löschung personenbezogener Daten nur dann durch Anonymisierung erfüllt werden, wenn die personenbezogenen Daten rechtmäßig erhoben wurden (vgl. Art. 17 Abs. 1 lit. a) DSGVO).
- Risiko einer Anonymisierung
Bei der Anonymisierung muss der Verantwortliche in der Regel von einem hohen Risiko ausgehen, da bei der Anonymisierung gerade regelmäßig das Kriterium „umfangreiche Verarbeitung“ und das Kriterium „neue Technologien“ zutrifft.
- Die Notwendigkeit der Durchführung einer Datenschutz-Folgenabschätzung ergibt sich daraus, dass die Erstellung eines anonymisierten Datenbestands eine komplexe Aufgabe für den Verantwortlichen darstellt und viele Fehlerquellen birgt.
- Dabei muss der Verantwortliche auch die Folgen einer möglichen Re-Identifikation (siehe zuvor) in die Überlegungen einzubeziehen.
- Vor der Durchführung einer Anonymisierung ist in der Regel eine Datenschutz-Folgenabschätzung durchzuführen.
- Technische Anonymisierungs-Werkzeuge
- Anonymisierung von strukturierten Daten
Strukturierte Datensätze bestehen aus einzelnen Datenelementen. In der tabellarischen Darstellung eines Datensatzes entspricht ein Datenpunkt einer Zeile der Tabelle. Jeder Datenpunkt des Datensatzes enthält Attribute, die konkrete Werte besitzen.
Es gibt eine Reihe von Verfahren, mit denen strukturierte Daten anonymisiert werden können. Welches Verfahren in Frage kommt, hängt unter anderem von der Art der zu anonymisierenden Daten, dem geplanten Verwendungszweck der Daten sowie den technischen und organisatorischen Rahmenbedingungen der Datennutzung ab. Die Art der Veränderung hängt vom gewählten Verfahren ab.
- Verfahren der Randomisierung
Im Wesentlichen werden bei der Randomisierung die Werte zufällig verändert. Diese Veränderung führt dazu, dass ein Zusammenhang zwischen verschiedenen Merkmalen aufgehoben wird. Dadurch werden Inferenzrisiken reduziert.
- Stochastische Überlagerung
Die Stochastische Überlagerung ändert die Werte einzelner Merkmale in einem Datensatz. Voraussetzung ist, dass die Werte numerisch, d.h. quantitativ sind. Weiterhin wird vorausgesetzt, dass die Originaldaten nach Anwendung des Verfahrens gelöscht werden, so dass die Veränderung nicht nachvollzogen werden kann.
- Vertauschung
Durch die Vertauschung werden die Merkmalswerte nicht verändert. Stattdessen werden die Werte zwischen den Datensätzen vertauscht. Das Verfahren eignet sich daher sowohl für quantitative Daten (Ratings, Listen) als auch für qualitative Daten. Voraussetzung ist, dass die Originaldaten nach der Anwendung gelöscht werden.
Nicht jede Vertauschung führt automatisch zu einer Anonymisierung. Es ist darauf zu darauf zu achten, dass die Merkmale vertauscht werden, die ursächlich für den Personenbezug sind.
- Anonymisierung durch Aggregation
Aggregationsbasierte Verfahren gruppieren einzelne Datenpunkte des Ursprungsdatensatzes. Die Gruppierung erfolgt dabei so, dass die Nutzbarkeit der Daten weitestgehend erhalten bleibt, aber das Risiko der Re-Identifikation und der Bestimmung von Attributwerten einzelner Personen reduziert wird. Die Aggregationsbasierte Anonymisierung wird seit langem angewandt und u.a. von der Statistik Austria genutzt.
Üblicherweise werden bei diesen Verfahren identifizierende Merkmale entweder generalisiert oder mittels sogenannter Mikroaggregation innerhalb der Gruppen durch repräsentative Werte ersetzt.
Generalisierung
Bei der Generalisierung wird beispielsweise das genaue Alter durch Fünfjahresintervalle ersetzt oder der genaue Beruf durch eine Qualifikationsstufe. Hier richtet die Gruppierung sich nach den vergröberten Merkmalen.
Mikroaggregation
Bei der Mikroaggregation hingegen werden grundsätzlich zuerst die Gruppen festgelegt und danach wird beispielsweise das individuelle Alter durch den Median des Alters innerhalb der Gruppe ersetzt.
U.a. gibt es folgende beliebte Aggregationsverfahren:
- Mondrian-Algorithmus
Einer der populärsten Ansätze ist der sogenannte »Mondrian-Algorithmus«. Dieser gruppiert zunächst alle Datenpunkte in eine einzige Gruppe. Diese wird dann unter Berücksichtigung des gewählten Anonymitätskriteriums in zwei neue Gruppen aufgeteilt. Für jede so entstandene Gruppe wird der Prozess der Teilung wiederholt, bis die neu entstandenen Gruppen das Anonymitätskriterium erfüllen.
- MDAV-Methode
Ein weiterer etablierter Ansatz ist die MDAV-Methode (MDAV steht für »Maximum Distance to Average Vector«), die in den Bereich der Mikroaggregation fällt und daher insbesondere für numerische Attribute geeignet ist. Hierbei werden die Datenpunkte nach ihrem Abstand zueinander gruppiert. Dazu werden zunächst Gruppen gebildet, die möglichst weit von der »Mitte« entfernt sind, so dass am Ende keine Datenpunkte am »Rand« übrigbleiben.
- Anonymisierung durch Rauschen
Prinzip des Rauschens
Bei der rauschbasierten Anonymisierung werden die Attributwerte eines Datensatzes durch künstlich erzeugtes statistisches Rauschen zufällig verändert. Dies führt dazu, dass der wahre Wert eines bestimmten Attributs nicht mehr mit Sicherheit bestimmt werden kann. Wie bei anderen Anonymisierungsverfahren wird auch hier die Nutzbarkeit der Daten eingeschränkt, da der Datensatz verfälscht wird.
- Anonymisierung durch Synthese
Eine Alternative zur Verwendung personenbezogener Daten ist die Verwendung synthetischer Daten. Synthetische Daten sind im Gegensatz zu personenbezogenen Daten nicht auf bestimmte natürliche Personen bezogen. Dementsprechend liefern sie auch keine Informationen über natürliche Personen. Vielmehr handelt es sich bei synthetischen Daten um Daten, die durch ein Berechnungsverfahren erzeugt werden.
- Prinzip der Synthese
Die Datensynthese anonymisiert Daten in einem zweistufigen Verfahren:
- Zunächst wird ein statistisches Synthesemodell an die Originaldaten angepasst.
- Mit Hilfe dieses Synthesemodells werden neue, synthetische Daten erzeugt.
I
- Angriffe auf anonymisierte Daten
- Angreifermodell
Ein Angreifer-Modell beschreibt also eine Methode, mit der geprüft wird, ob eine Re-Identifikation von anonymisierten Daten möglich ist. Erst wenn ein solcher – ernsthalt durchgeführter – Versuch scheitert, kann von anonymen Daten gesprochen werden.
Ein Angreifer kann verschiedene Ziele verfolgen, um Personen in einem anonymisierten Datensatz zu re-identifizieren. Je wertvoller die Daten für den Angreifer sind, desto mehr Fachwissen und Ressourcen müssen vorausgesetzt werden. Dabei sind nicht alle theoretisch denkbaren oder nicht auszuschließenden technischen Möglichkeiten oder möglicherweise vorhandenes Wissen einzubeziehen, sondern die wahrscheinlichsten.
- Angriffsmethoden
Angriffsmethoden, mit denen diese Ziele erreicht werden können, müssen in der Regel an die jeweils Anonymisierungsverfahren angepasst werden: So müssen durch Datensynthese anonymisierte Datensätze anders angegriffen werden als solche, die durch Aggregation oder Hinzufügen von Rauschen erzeugt wurden. Zudem benötigt der Angreifer in der Regel Kontextinformationen über einzelne Personen, die er mit den anonymisierten Daten abgleichen kann.
Grundsätzlich ist es für einen Angreifer umso einfacher, Personen in einem anonymisierten einem anonymisierten Datensatz zu de-anonymisieren, je mehr relevante Kontextinformationen er über die Personen hat und je genauer er das zur Anonymisierung verwendete Verfahren kennt. Die Geheimhaltung des Anonymisierungsverfahrens kann daher eine sinnvolle Sicherheitsmaßnahme sein; die Kenntnis des Verfahrens allein dürfte die Wahrscheinlichkeit einer erfolgreichen De-Anonymisierung für einen Angreifer jedoch nicht wesentlich erhöhen.
Um eine quantitative Aussage über die Wahrscheinlichkeit der Re-Identifikation einer Person zu machen und Attributwerten der Person zu treffen, wird häufig ein formales Angriffsmodell definiert und mit einem Testdatensatz definiert und mit einem Testdatensatz evaluiert. Ein solches Modell kann für einen gegebenen Datensatz mit unterschiedlichen Metriken evaluieren werden.
- Best Practices
- Anonymisierung Vorgehensmodell
In diesem Kapitel wird ein Vorgehensmodell für die Anonymisierung erläutert.
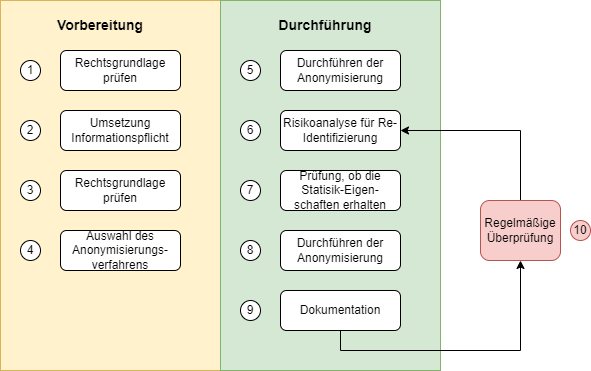
Einen Überblick über die in der Regel einschlägigen Rechtsgrundlagen gibt die folgende Tabelle. Welche Rechtsgrundlage eine konkrete Anonymisierung erlaubt, ist im Einzelfall zu prüfen.
- Tools zur Anonymisierung
Im Folgenden werden einige Tools zur Anonymisierung aufgelistet:
| Tool | Institution | Country | Platform | Release | LastUpdate | License | Link |
| Amnesia | TMF – Technologie- und Methodenplattform | GER | Amnesia | ||||
| Anon | University of Klagenfurt | AUT | Java | 2012 | ANON | ||
| ARX | BIH@Charite | GER | Java | 2012 | 2022 | Apache | ARX |
| Materialise Mimics 21.0 | UN Global Impact | Materialise Mimics 21.0 | |||||
| Open Anonymyzer | Universyty of Vienna | AUT | Java | 2008 | 2009 | ? | Open Anonymizer download | SourceForge.net |
| Quali Anon | Universität Bremen | GER | QualiAnon | ||||
| PrioPrivacy | Research Stidio Data Science | AUT | Java | 2019 | 2021 | PrioPrivacy | |
| Projekt A | ainovi GmbH | GER | 0-15€ / Nutzer/ Monat | Projekt A | |||
| sdcMicro | Statistics Austria | AUT | R | 2007 | 2021 | GPL 2 | Das umfassende R-Archiv-Netzwerk (r-project.org) |
| Tiamat | Purdue University | USA | Java | 2009 | ? | „TIAMAT” |
- Quellenangaben
Positionspapier-Anonymisierung.pdf des
ISO 29100:2011; Petrlic/Sorge, Datenschutz: Einführung in technischen Datenschutz, Datenschutzrecht und angewandte Kryptographie, 2017, S. 13; Paal/Pauly/Ernst, DS-GVO, Art. 4 Rn. 48
BDSG Bundesdatenschutzgesetz Deutschland
Anonymisierung und Pseudonymisierung von Daten für Projekte des maschinellen Lernens (bitkom.org)
SDS_Studie_Praxisleitfaden-Anonymisieren-Web_01.pdf (stiftungdatenschutz.org)
Arbeitshilfe zur Pseudonymisierung/Anonymisierung (gesundheitsdatenschutz.org)
- Schlussbemerkung
Anonymisierung ist ein wichtiges Verfahren, um die Risiken für betroffene Personen bei der Verarbeitung ihrer personenbezogenen Daten zu verringern. Daher sollte sie immer eingesetzt werden, wo immer es sinnvoll ist.
Es gibt eine Vielzahl von Verfahren, mit denen Daten in der Praxis anonymisiert werden können. Welches Verfahren im Einzelfall geeignet ist, hängt im Wesentlichen vom Format der zu schützenden Daten und dem Verwendungszweck ab. Je nach Anwendung können statische, dynamische oder interaktive Verfahren eingesetzt werden. Neben der technischen Eignung des Anonymisierungsverfahrens sollte immer auch geprüft werden, ob das Verfahren geeignet ist, alle bekannten und relevanten Risiken für die Personen, deren Daten anonymisiert werden sollen, wirksam zu reduzieren
Das Tagebuch wird zur Verfügung gestellt von:










Be the first to comment